
What’s the Real Difference Between Text-to-Speech and Speech-to-Text in 2025?
Explore the advanced differences between Text-to-Speech (TTS) and Speech-to-Text (STT) technologies. Learn how AI voice tools are reshaping accessibility, creativity, real-time translation, and user experience in modern digital systems.
AI ASSISTANTAI/FUTURECOMPANY/INDUSTRYEDUCATION/KNOWLEDGE
Sachin K Chaurasiya
6/20/20256 min read


In a world increasingly driven by voice commands, smart devices, and conversational AI, two groundbreaking technologies are quietly reshaping how we interact with the digital universe: Text-to-Speech (TTS) and Speech-to-Text (STT). While they serve opposite purposes—one speaks what you write, the other writes what you speak—both are at the core of everything from virtual assistants to real-time translation, accessibility tools, and AI-driven content creation.
But what really sets them apart? Which one is right for your needs? And how are advancements like voice cloning, neural synthesis, and emotion-aware transcription changing the game?
In this article, we’ll dive deep into the technical differences, real-world use cases, and AI-powered future of TTS and STT—helping you understand not just what they are, but how to use them wisely in a world that's increasingly driven by voice-first interactions.
What Is Text-to-Speech (TTS) Technology?
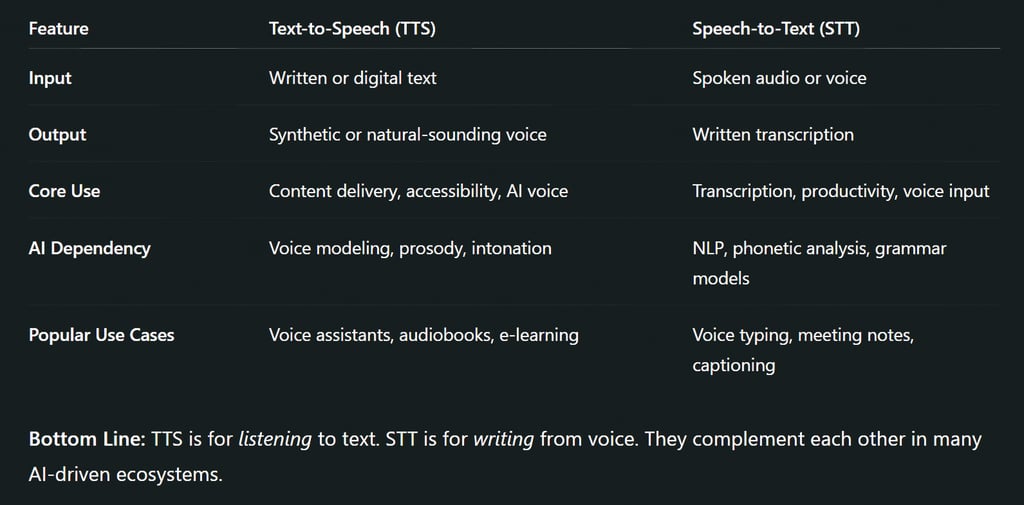
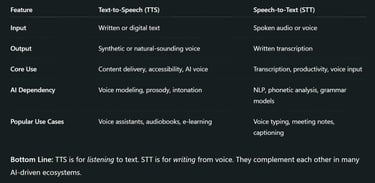
Text-to-Speech (TTS), commonly known as TTS, is a form of assistive technology that reads digital text aloud. Using AI-driven voice synthesis, it converts written words into spoken audio in real time. TTS is often used in e-learning, accessibility for visually impaired users, voice assistants (like Alexa and Siri), and content narration.
Key Features of TTS
Converts digital text into natural-sounding speech
Supports multiple languages and voice options
Used in audiobooks, screen readers, navigation systems, and chatbots
Popular Tools
Google Cloud Text-to-Speech, Amazon Polly, IBM Watson TTS, Microsoft Azure Speech
What Is Speech-to-Text (STT) and How Does It Work?
Speech-to-Text (STT) is a voice recognition technology that transcribes spoken words into written text. It leverages machine learning and natural language processing (NLP) to detect speech patterns, convert audio input into readable content, and handle various accents and speech speeds.
Key Features of STT
Real-time or recorded voice transcription
Punctuation and language detection
Useful in meetings, interviews, accessibility apps, and voice typing
Popular Tools
Google Speech-to-Text, Otter.ai, Apple Dictation, Microsoft Azure Speech-to-Text
Why Are TTS & STT So Important in Today’s AI World?
In an AI-dominated world, voice interfaces are rapidly becoming the new norm. Both TTS and STT are foundational in:
Smart Assistants (like Alexa and Google Assistant): STT converts your commands; TTS gives a voice to the AI.
Education & E-learning: TTS supports auditory learners, while STT allows note-taking via speech.
Accessibility: Visually impaired users benefit from TTS, while those with motor disabilities use STT for control.
Content Creation & Productivity: TTS reads content for better comprehension; STT speeds up writing via dictation.
Voice is becoming the interface, and these two technologies make it human-centric and accessible.
Which Is Better for Accessibility: TTS or STT?
The answer depends on the user's needs:
For Visually Impaired Users: TTS is essential. It gives them access to web pages, documents, emails, and more through voice.
For Users with Physical Disabilities: STT is a life-changer. It allows hands-free typing, web navigation, and communication.
How to Choose the Right Technology for Your Use Case?
Ask yourself these practical questions:
Do I need to convert written content into spoken form? → Use Text-to-Speech.
Do I want to type or control apps using my voice? → Use Speech-to-Text.
Do I need real-time communication or transcription? → STT tools like Otter.ai or Whisper are ideal.
Am I building a voice-enabled app or assistant? → Combine TTS for response + STT for commands.
Pro Tip: Many modern tools (like Google Cloud or Azure AI) integrate both TTS and STT into a single platform for seamless interaction.
Can Text-to-Speech & Speech-to-Text Work Together?
Absolutely! In fact, most smart systems today combine both:
Virtual Assistants: STT understands your query; TTS answers it aloud.
Customer Support Bots: STT logs your problem, and TTS reads back solutions.
Language Learning Apps: You speak, it transcribes (STT), then reads correct sentences (TTS).
This symbiotic relationship between input and output makes interfaces more natural, conversational, and user-friendly.

Neural TTS & Whisper STT: The Game Changers
Neural Text-to-Speech (NTTS)
Traditional TTS systems used concatenative or parametric methods (like HMMs), which sounded robotic. NTTS, introduced by companies like Google (Tacotron 2), Amazon, and Microsoft, uses deep neural networks to replicate the nuances of human speech—such as emotion, stress, and breathing.
Features of Neural TTS
Emotional speech rendering (e.g., cheerful, sad, angry tones)
Pause and inflection control
Near-human naturalness, even in complex paragraphs
Whisper by OpenAI (for STT)
Whisper isn’t just another speech recognition system. It was trained on 680,000 hours of multilingual and multitask supervised data from the web. It can:
Transcribe with high accuracy even in noisy environments
Perform translation (STT + translation in one go)
Understand multiple accents and dialects


Custom Voice Cloning & Personalized Speech Models
Voice Cloning (TTS)
Now you can train a model on just a few minutes of audio to recreate your voice using TTS. Tools like Resemble.ai, ElevenLabs, and Play.ht offer voice cloning for branding, gaming, and even continuity in films (e.g., aging actors or characters with legacy voices).
Risks & Ethics
Deepfake Voices: Voice cloning can be misused for fraud, fake news, or impersonation.
Consent & IP: Artists and creators now demand platforms ensure voice cloning happens only with explicit consent.
Custom Vocabulary in STT
Speech-to-text is evolving to support domain-specific transcription, like
Medical dictation (understanding terms like “angioplasty” or “tachycardia”)
Legal transcription (capturing structured statements and clauses)
Multimodal AI: Combining Voice with Vision and Text
The future lies in multimodal AI, where speech, vision, and text interact seamlessly.
Imagine This
You say, “This plant looks unhealthy.” → STT transcribes your voice
AI vision analyzes the plant via camera
TTS replies, “The leaves show fungal spots. Consider using neem oil.”
Both TTS and STT are now being embedded in robots, AR glasses, and mixed reality environments, creating real-time, interactive digital humans and assistants.
Biases, Language Gaps, & Global Inclusion
Despite their power, both TTS and STT still struggle with
Accent Bias: Heavier accents from rural or underrepresented regions result in lower STT accuracy.
Tonal Languages: TTS for Mandarin, Thai, or Vietnamese requires special training due to pitch-dependent meanings.
Digital Colonialism: Most AI voice models are optimized for Western languages, neglecting many African, indigenous, or regional Indian languages.
Emerging Efforts
Mozilla Common Voice and Indic TTS projects are crowdsourcing multilingual voice data to close this gap.
Google is now training STT for code-mixed languages like Hinglish (Hindi + English), which are common in India.
Integration with Real-Time Translation Systems
Advanced systems now merge STT → Translation → TTS in real-time:
Example
You say in Spanish, “¿Dónde está la farmacia?”
STT transcribes the audio
NLP translates it to English: “Where is the pharmacy?”
TTS reads it out instantly in English
This is the backbone of real-time translation devices like Pocketalk, Travis Touch, or Google Pixel Buds.
Voice AI in Creative Media & Entertainment
In Filmmaking & Games
STT tools are used for live script annotation, helping directors tag improvisation.
TTS with cloned actor voices is used to replace bad audio, saving production costs.
In Podcasts and Audiobooks
AI-generated voices are now hosting entire podcasts, especially in non-English markets.
TTS can simulate multiple characters in audiobooks, complete with emotion and dialogue variation.


FAQs
What is the difference between Text-to-Speech and Speech-to-Text?
Text-to-Speech (TTS) converts written text into spoken audio, while Speech-to-Text (STT) transcribes spoken language into written text. TTS is used for reading content aloud; STT is used for voice input and transcription.
Which is better for accessibility: TTS or STT?
Both serve different accessibility needs. TTS helps visually impaired users by reading digital content aloud, while STT supports users with motor disabilities by allowing voice-based typing and control.
Can Text-to-Speech & Speech-to-Text work together in the same application?
Yes, many applications like virtual assistants, translation tools, and AI chatbots integrate both. STT captures user speech, and TTS delivers the system’s response audibly.
Are TTS & STT accurate in noisy environments or with accents?
Modern AI models like OpenAI's Whisper and Google's DeepMind have improved accuracy across accents and background noise, but performance can still vary based on language, pronunciation, and training data quality.
What are some advanced uses of TTS & STT in AI today?
Advanced applications include AI voice cloning, emotional speech rendering, real-time multilingual translation, live content moderation, podcast automation, and immersive storytelling in games and films.
Is voice cloning with TTS ethical & safe?
Voice cloning raises ethical concerns, especially around consent and misuse. Reputable platforms ensure voice data is used with permission and protect cloned voice content through watermarking and licensing.
Instead of asking which one is better, ask how both can enhance your digital experience. Whether you're designing AI applications, building accessibility tools, or increasing productivity, understanding and using both TTS and STT will future-proof your workflow.
Subscribe To Our Newsletter
All © Copyright reserved by Accessible-Learning Hub
| Terms & Conditions
Knowledge is power. Learn with Us. 📚

