
What Is Vidu AI? The Chinese Sora Alternative Explained
Discover Vidu AI — China's powerful answer to OpenAI’s Sora. Explore how this text-to-video model works, its technical depth, unique cultural strengths, and why it matters in the global race for generative AI video dominance.
AI ART TOOLSEDITOR/TOOLSAI/FUTUREARTIST/CREATIVITY
Sachin K Chaurasiya
6/10/20257 min read


What Is Vidu AI?
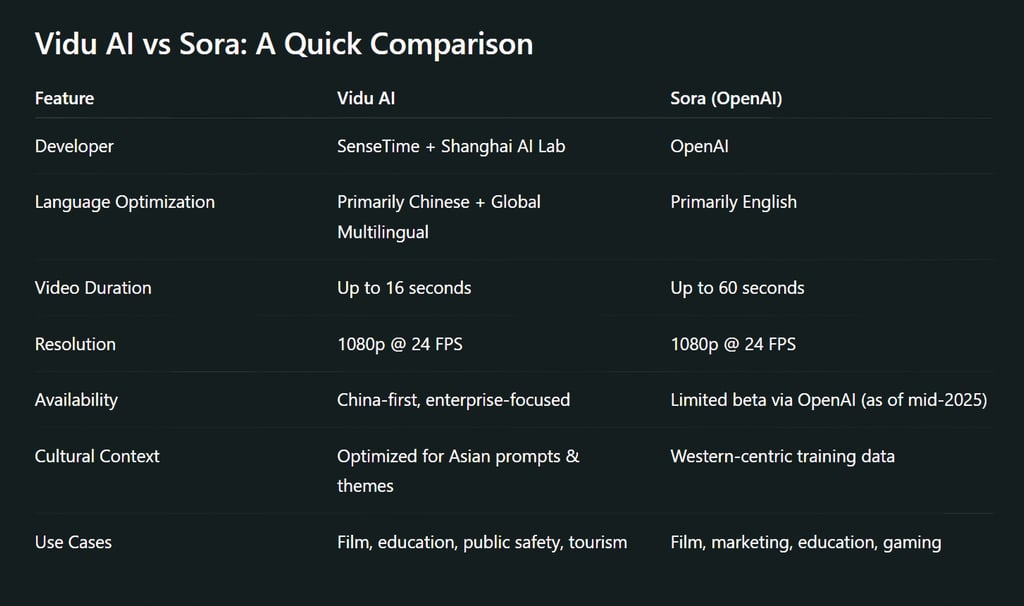
Vidu AI is a cutting-edge text-to-video generative AI model developed by Chinese tech giant ShangTang Technology (SenseTime) in collaboration with Shanghai Artificial Intelligence Laboratory. Often dubbed the Chinese Sora, Vidu is designed to convert text prompts into realistic, high-definition video clips — directly competing with OpenAI’s groundbreaking model, Sora.
Launched in April 2024 during the 2024 Zhongguancun Forum, Vidu has caught the world’s attention for being one of the most sophisticated video generation models developed outside the U.S., reflecting China’s growing prowess in AI innovation.
Who Developed Vidu AI?
Vidu AI is the result of collaborative work between
SenseTime (ShangTang Technology): A leading Chinese AI company known for facial recognition, computer vision, and autonomous driving technologies.
Shanghai AI Laboratory: A major research center backed by Chinese government bodies and tech firms like Alibaba and Huawei.
Together, they developed Vidu under the “Open Source, Open Innovation” philosophy, aiming to position China as a major player in the generative AI space.
How Does Vidu AI Work?
Vidu AI uses a large multimodal diffusion model (inspired by diffusion models like those used in DALL·E and Sora) to generate videos from natural language text prompts. The process involves
Text Encoding: The user inputs a descriptive prompt (e.g., “a panda drinking tea under a cherry blossom tree”).
Scene Composition: Vidu breaks down the text into visual elements using natural language processing and scene understanding.
Video Synthesis: Using trained AI diffusion techniques, it composes a sequence of video frames with dynamic movement, background realism, and character consistency.
Rendering: The final output is a high-definition, coherent video — up to 16 seconds long as of current capabilities.
What Makes Vidu AI Unique?
While comparisons to Sora are inevitable, Vidu AI brings some distinctive features:
Alignment with Chinese Aesthetics and Language
Vidu has been trained heavily on Chinese cultural, environmental, and linguistic data, making it more capable of understanding prompts in Mandarin and producing outputs that resonate with regional storytelling, art, and landscapes.
Real-Time Video Rendering at High Frame Rates
Vidu can generate 1080p videos at 24 FPS, which matches Sora’s early outputs. It maintains strong temporal consistency — meaning objects and characters stay realistic and cohesive across frames.
Deep Integration with Chinese Tech Ecosystem
Vidu is expected to integrate with Chinese platforms such as WeChat, Douyin (TikTok China), Bilibili, and enterprise solutions in education, tourism, and film.

Why Vidu AI Matters
Vidu AI represents more than just a technical achievement — it’s a strategic response to Western AI dominance. By creating a homegrown solution rivaling Sora, China is
Enhancing AI sovereignty
Boosting national pride in tech innovation
Opening new markets for media automation
Providing alternatives to U.S.-based AI services
Vidu is also part of a broader Chinese vision to lead in AI governance, open-source development, and responsible AI deployment.
Applications & Real-World Use Cases
Vidu AI is already being piloted in several sectors:
Film & Animation: Quickly generate pre-visualizations, concept trailers, and animations from script lines.
Education: Create video content for history, science, and language learning from curriculum text.
Tourism & Culture: Recreate historical events or showcase destinations in short promotional videos.
Public Safety Training: Simulate realistic environments for emergency drills or urban planning.
Limitations & Challenges
While Vidu is impressive, it’s not without its challenges:
Limited Prompt Diversity: Still evolving in handling complex, ambiguous, or abstract prompts in non-Chinese languages.
Short Video Duration: Currently capped at 16 seconds.
Restricted Access: Mostly enterprise and institutional users can access it; it's not publicly open like Runway or Pika.
Ethical Oversight: The Chinese government’s strict content controls may limit creative freedom for some users.
Vidu's Multimodal Diffusion Architecture
Vidu AI is built upon a multimodal diffusion-based transformer framework, similar in concept to OpenAI’s Sora, but localized for Chinese datasets and hardware optimization.
Base Architecture: Inspired by Latent Diffusion Models (LDM) and DiT (Diffusion Transformer) hybrids.
Text Encoding: Utilizes a fine-tuned Chinese LLM based on models like InternLM, ChatGLM, or a proprietary variant trained on culturally contextual datasets.
Temporal Modeling: Employs a spatiotemporal attention mechanism for coherent motion across frames, allowing Vidu to manage complex object trajectories and action continuity — a common weakness in other models.


Motion & Physics Simulation
A standout feature of Vidu is its "world simulation engine"—a" physics-aware layer that simulates realistic interactions between characters, objects, and environments.
Scene Consistency: Vidu can generate physics-consistent motion like splashes, shadows, wind-driven movements, and object deformations.
Gravity-aware Modeling: It estimates and applies gravity vectors to objects like falling leaves, hair sway, or thrown objects to simulate real-world dynamics.
Material Behavior Modeling: It distinguishes materials (glass, cloth, water, metal) to generate visually appropriate reactions.
This is inspired by game engines like Unity and Unreal but driven by AI-generated data rather than physics equations.
Text-to-Video Prompt Understanding in Mandarin NLP
Unlike Western models trained on English-centric corpora, Vidu is optimized for Chinese natural language, idioms, metaphors, and poetic imagery.
Semantic Comprehension Layer: Built on top of massively pre-trained Chinese transformers, it can interpret four-character idioms, Confucian or Taoist symbolism, and metaphorical visuals.
Prompt Decomposition: Uses dependency parsing and visual lexicon mapping to convert poetic or literary phrases into a structured visual storyboard.
Training Data & Optimization
Vidu AI is trained on terabytes of synthetic and real-world Chinese video datasets, curated across diverse fields:
Sources: Public Chinese video datasets, proprietary educational/cultural media, cinematic footage, and surveillance-style datasets (for realism).
Frame-Level Captioning: Each frame was paired with fine-grained Chinese captions, using self-supervised learning and human annotations.
Noise Scheduling: Advanced denoising techniques with adaptive schedulers (inspired by DDPM++ and EDM) to maintain visual quality at 24 fps.
Optimization for training is done on local high-performance GPU clusters, potentially using Huawei Ascend chips in addition to NVIDIA H100s, to reduce reliance on U.S.-restricted hardware.
Scene & Object Persistence: Memory-Augmented Attention
Vidu handles long video coherence using a persistent memory attention layer:
Memory Tokens: Specialized vectors store identities and poses of objects/characters across frames.
Multi-layer Attention Sync: Ensures a cat walking in frame 1 remains the same cat (with consistent shape, fur pattern, and orientation) in frame 30.
Scene Anchoring: Backgrounds and lighting conditions are treated as temporal anchors to reduce scene flickering or drift.
This technique allows better continuity than many competitors, especially those struggling with object identity shifts.
Model Size & Inference Capabilities
Though exact parameters haven’t been disclosed, speculative analysis suggests:
Model Size: 10–20 billion parameters (base model), plus auxiliary models for scene control, audio simulation (future roadmap), and motion prediction.
Token Size: Uses spatial tokens + temporal tokens to build a 3D attention structure (Time × Height × Width).
Inference: Likely optimized using ONNX + TensorRT or MindSpore (Huawei) for real-time edge deployment and faster rendering on domestic chips.
Future Capabilities & Research Roadmap
The Shanghai AI Lab has hinted at expanding Vidu’s scope into multimodal storytelling engines:
Audio Generation: Adding natural soundscapes and dialogue directly from text.
Lip-syncing and facial expression modeling.
Interactivity: Enabling Vidu to generate branching narratives or game-style videos with prompt-based interactivity.
Long-Form Video (>60 seconds): Ongoing work in hierarchical scene stitching using multi-shot memory graphs to go beyond the current 16s limit.
Alignment, Control, & Safety Layers
Vidu AI includes strict Chinese regulatory alignment layers, which differ from Western content moderation:
Content Filtering: On-prompt and post-generation filters to block content that violates cultural, political, or religious guidelines.
Style Control Tokens: Embedded tokens to control video tone (serious, cute, solemn, celebratory), character types, or artistic aesthetics (ink painting, realistic, anime, etc.).
Human-in-the-Loop Feedback: Especially for institutional or government use, a manual review layer may intervene before video deployment.

FAQs
Q: Is Vidu AI better than Sora?
Vidu is competitive, especially for Mandarin-based prompts and Chinese cultural themes. Sora currently leads in length and global usability.
Q: Can I use Vidu AI in English?
It supports English prompts, but it performs best with Chinese. Multilingual support is expected to improve over time.
Q: How do I access Vidu AI?
As of now, Vidu is available through enterprise partnerships and research collaborations in China.
Q: Is Vidu AI open-source?
While it promotes open innovation, the core model is not fully open-source yet, unlike some Western models.
Q: What industries will benefit most from Vidu AI?
Film, education, tourism, and public sector training are early adopters in China.
Q: How does Vidu AI differ from OpenAI’s Sora?
Vidu AI and Sora are both text-to-video generation models, but Vidu is localized for Chinese prompts, culture, and language. It uses Chinese-pretrained language models and datasets, while Sora is built around English-language and globally diverse content. Vidu also prioritizes alignment with Chinese regulations.
Q: What makes Vidu AI technologically unique?
Vidu AI employs a hybrid of diffusion transformers, memory-augmented attention, and physics-aware modeling. It ensures high visual fidelity, continuity, and culturally nuanced content generation that outperforms many in scene persistence and object motion logic.
Q: Can Vidu AI generate long videos like Sora?
As of now, Vidu AI supports videos up to 16 seconds at 1080p, 24 fps. The development roadmap includes plans to extend this to longer-form content using hierarchical stitching and memory-based temporal modeling.
Q: Is Vidu AI available for public or commercial use?
Currently, Vidu AI is in closed beta or research use only. It is developed by Shanghai AI Lab in partnership with SenseTime and other Chinese AI firms. Wider access for developers and creators is expected in phases.
Q: What languages does Vidu AI support?
Vidu AI primarily supports Chinese-language prompts, with a strong understanding of Mandarin NLP, idioms, and poetic structure. It is not yet optimized for English or multilingual usage.
Q: What kind of prompts work best with Vidu AI?
Culturally rich, descriptive, and poetic Chinese prompts yield the best results. Examples include idioms (成语), historical or mythical themes, seasonal imagery, and folk tales. It handles abstract and narrative-rich prompts well.
Q: Is Vidu AI trained using real-world Chinese videos?
Yes. Vidu is trained on large-scale Chinese video datasets sourced from educational, cinematic, surveillance, and synthetic environments, all annotated for frame-level context and motion logic.
Q: Does Vidu AI support stylized video generation (e.g., anime, painting styles)?
Yes. Vidu includes style control tokens that allow creators to guide the visual output into anime-style, ink-wash (水墨), cinematic, or ultra-realistic renders, depending on prompt and config.
Q: How does Vidu AI ensure alignment and safety?
Vidu incorporates strict alignment with Chinese regulatory standards, using advanced content moderation, NSFW detection, political content filters, and manual oversight for institutional deployments.
Vidu AI is not merely a local imitation of Sora — it is a regionally engineered marvel, leveraging language-specific intelligence, hardware diversity, and governance-aligned design. While Sora might excel in broader cinematic versatility today, Vidu excels in precision localization, scene fidelity, and cultural resonance.
As China expands its AI infrastructure and reduces reliance on foreign GPUs, tools like Vidu will likely scale in length, quality, and accessibility, reshaping not just Chinese video creation but the global AI media ecosystem.
Subscribe To Our Newsletter
All © Copyright reserved by Accessible-Learning Hub
| Terms & Conditions
Knowledge is power. Learn with Us. 📚

