
Vidu AI vs VEO 3 vs Sora AI: A Deep Dive into the Future of AI-Powered Video Creation
Discover the differences between Vidu AI, VEO 3, and Sora AI—three leading AI video generation tools. Explore their advanced technologies, use cases, architectures, and future potential in cinematic storytelling, simulation, and social content.
AI ASSISTANTA LEARNINGAI/FUTUREEDITOR/TOOLS
Sachin K Chaurasiya
6/24/20256 min read


AI video generation has evolved from a niche experiment into a full-scale technological revolution. Today, tools like Vidu AI, Google DeepMind’s VEO 3, and OpenAI’s Sora are setting new standards in how we imagine, create, and experience video content. Whether you're a filmmaker, educator, digital marketer, or content creator, understanding these tools is crucial.
This comparison explores the core differences, use cases, innovations, limitations, and future directions of these three top-tier AI video tools to help you decide which one best aligns with your creative or professional needs.
Vidu AI: Speed & Cultural Precision from China
What Is Vidu AI?
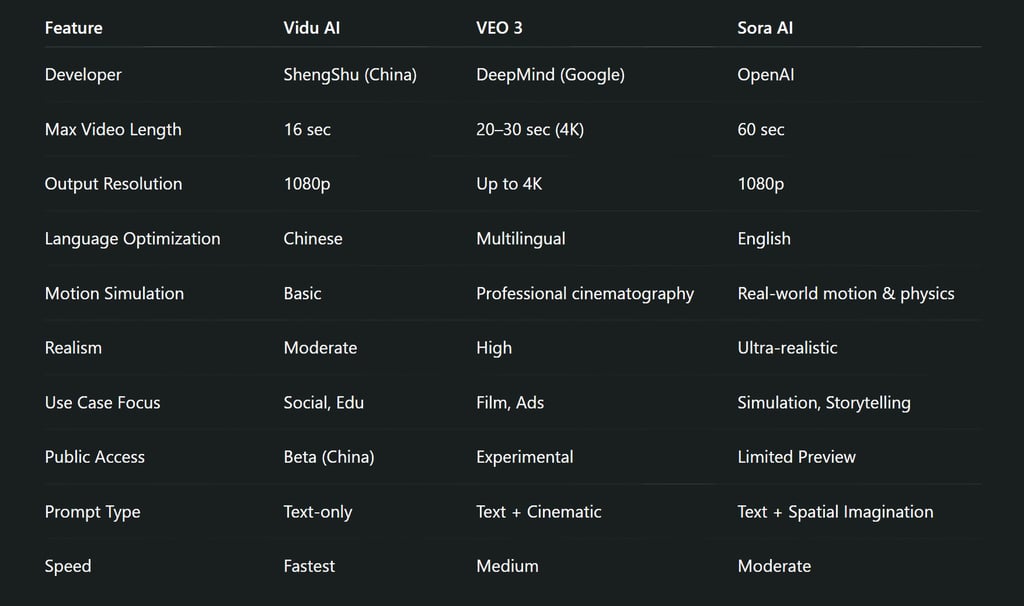
Developed by ShengShu Technology (linked to Tsinghua University and the Tiangong Institute), Vidu AI is a fast, highly efficient text-to-video model with a deep understanding of Chinese language, culture, and style.
Though less internationally known than Sora or VEO, Vidu AI has captured attention for being the first major Chinese AI to rival OpenAI in text-to-video generation. Its main strength lies in speed—generating short videos in seconds—and localized intelligence.
Technical Highlights
Transformer-style architecture inspired by Sora
Diffusion-based video synthesis model
Supports prompt-to-video in under 10 seconds
Integrated natural language understanding engine for Chinese dialects
Strengths
High-speed output
Cultural nuance for Chinese media, social platforms, education
Compact video generation (ideal for platforms like Douyin and Kuaishou)
Limitations
Language limitations (not well optimized for English prompts yet)
Lower realism than Sora or VEO
Restricted to 16-second outputs
Training Strategy & Data Composition
Training Strategy: Chinese-centric corpus of text-video pairs, heavily augmented with synthetic narratives and motion overlays.
Special Feature: A "semantic-speed" loss function was implemented to match video tempo with linguistic tone (especially for Mandarin tonal markers).
Data Size: Estimated 4B parameter range, trained on Chinese TikTok-like video content and public education videos.
Temporal Consistency & Memory Modeling
Uses static cache embeddings for up to 16 seconds.
Lacks long-form memory modeling due to token length limits.
Scene Graph & Spatial Reasoning Layer
Basic 2D segmentation masks for characters and props.
No 3D or layered occlusion simulation—primarily works in 2.5D.
Computational Pipeline & Inference Stack
Real-time inference using edge TPU optimization on Kunlun chips
Client-side rendering optional for enterprise deployment
Model sharded across lightweight mobile inference modules


VEO 3: Google’s Cinematic AI Engine
What Is VEO 3?
VEO 3 is Google DeepMind’s flagship text-to-video diffusion model that debuted during Google I/O 2024. This tool is engineered for cinema-level quality, capable of interpreting prompts with visual finesse, dynamic lighting, camera movement, and narrative flow.
Google trained VEO using its massive compute infrastructure and leveraged Imagen 2, Phenaki, and Lumiere technologies to create a model focused on temporal coherence, scene consistency, and professional-grade cinematic results.
Technical Highlights
Uses latent diffusion and space-time coherence models
Trained on high-fidelity cinematic datasets
Resolution up to 4K, with high dynamic range
Camera movement simulation: dolly shots, pans, zooms
Strengths
Produces movie-like visuals
Great for storytelling, trailers, advertising, and narrative visual content
Extensive visual vocabulary for cinematic shots
Built-in cinematic prompt stylizer (e.g., “in the style of a Wes Anderson film”)
Limitations
Limited public access (currently invite-only)
Longer render times than Vidu AI
Requires precise and artistic prompts to achieve ideal results
Training Strategy & Data Composition
Training Strategy: Multi-modal joint training using Phenaki’s video tokenization + Imagen 2’s text diffusion + curated cinema datasets (e.g., Creative Commons short films, YouTube Shorts).
Progressive Attention Layers allow it to model narrative arcs over time, maintaining visual themes like lighting or object continuity.
Unique Technique: Implements V-Consistent Diffusion, which anchors visual subjects through time using motion-consistent latents.
Temporal Consistency and Memory Modeling
Incorporates a Long-Term Latent Anchor Buffer (LLAB) that tracks objects across scenes.
Effective at simulating storytelling arcs (e.g., maintaining the same character design and position across multiple angles).
Scene Graph & Spatial Reasoning Layer
Deploys 3D spatial scene graphs (with physics-blind logic), tracking characters and background as layered planes.
Scene transitions are interpolated via optical flow estimation.
Computational Pipeline & Inference Stack
Runs on Google’s Pathways TPU v5e
Multistage processing:
Stage 1: Prompt parsing
Stage 2: Latent video generation
Stage 3: High-resolution upscaling using Imagen2
The final stage includes cinematic filter application (optional)


Sora AI: OpenAI’s World-Model for Video
What Is Sora?
Sora, introduced by OpenAI in early 2024, is more than a video generator—it’s a world simulation engine. Trained not only on video and image data but also on physics, spatial logic, and dynamic object interactions, Sora can produce photorealistic videos up to 60 seconds long, with breathtaking detail.
Unlike other models that interpolate frames, Sora models a virtual world frame-by-frame with realistic depth, motion, materials, and environmental feedback.
Technical Highlights
Built on autoregressive transformer architecture
Understands depth, lighting, 3D space, and physical realism
Can simulate camera movements, object interactions, weather effects
Supports videos with multiple characters, long dialogues, and natural transitions
Strengths
Best-in-class realism and world consistency
High tolerance for complex prompts (e.g., “a drone flies through a storm”)
Long-duration videos (up to 60 seconds)
Strong potential for education, gaming, science, storytelling
Limitations
Still under limited access
Can hallucinate or distort visuals in extremely abstract prompts
Higher computational requirements compared to other models
Training Strategy & Data Composition
Training Strategy: Trained on petabytes of data, including simulated environments, scientific visualizations, drone footage, and live-action video.
Multi-modal Fusion: Combines temporal audio-visual embeddings and world-state predictions to generate causally plausible scenes.
Frame Persistence Index: Sora models how each object affects its environment from frame to frame—like shadow casting, debris, ripple effects, etc.
Temporal Consistency and Memory Modeling
Utilizes Frame-to-World Memory Tokens, where each frame updates a "world model" memory.
Models occlusion, object permanence, and collision logic during motion or camera transitions.
Scene Graph & Spatial Reasoning Layer
Advanced 4D spatiotemporal modeling: each object includes position, velocity, material, and interaction signature.
Simulates depth, parallax, and kinetic chain reactions (e.g., wind affects fabric or falling objects cause ripples).
Computational Pipeline & Inference Stack
Sora is backed by OpenAI's custom Nvidia DGX Cloud infrastructure
Massive transformer windowing (supports >2000 time steps)
Uses a probabilistic replay engine to rerender parts of a scene if the physics logic is broken


Creative & Commercial Use Scenarios
Content Creators & Social Media
Vidu AI wins for speed and short-form video.
Sora offers realism for high-impact storytelling.
VEO creates film-style clips for high-end reels.
Filmmakers & Advertisers
VEO 3 is tailored for cinematic quality.
Sora can act as a virtual set or animation engine.
Vidu AI is less suited for long-form or detailed shots.
Educators & Scientists
Sora is ideal for scientific simulations, biology, physics, and climate change.
Vidu AI suits educational short videos in Chinese.
VEO works well for visual essays and documentary segments.
Developers & Simulators
Sora could become foundational for game development, XR, or interactive cinema.
Vidu and VEO are more for pre-rendered content than real-time engines.
What’s Coming Next?
Vidu AI Roadmap
Expansion into multilingual prompts
30-second output update expected by late 2025
Possible integration with voice-to-video input
VEO 3 Roadmap
Public release (expected Q4 2025)
Generative audio and sound FX pipeline
Scene-based editing with timeline control
Sora AI Roadmap
Transition toward interactive storytelling
Integration with voice, music, dialogue
Plug-ins for Unity, Unreal, and Blender in R&D phase



Each platform is excelling in a unique domain:
Vidu AI is fast and culturally tuned for short-form Chinese content—excellent for real-time creators and educators.
VEO 3 is cinematically brilliant, offering creative control for advertisers, filmmakers, and visual artists.
Sora AI is the most technically advanced, designed for realistic world simulation, education, and immersive storytelling.
As AI models become more accessible and integrated, these tools are likely to merge capabilities—leading to future platforms that blend realism, artistry, interactivity, and speed.
FAQs
What is the main difference between Vidu AI, VEO 3, and Sora AI?
Vidu AI is focused on real-time, fast video generation with Chinese-language optimization; VEO 3 emphasizes cinematic storytelling and visual consistency using Google’s powerful diffusion models; Sora AI by OpenAI is designed to simulate real-world physics and causality with high realism and long-form memory.
Which AI video tool is best for storytelling or cinematic content?
VEO 3 is best suited for cinematic content thanks to its latent diffusion temporal model and long-term object tracking, which ensure visual narrative flow and aesthetic coherence.
Is Sora AI capable of generating realistic videos with physical accuracy?
Yes, Sora AI is engineered to simulate real-world interactions, depth, and object persistence using a world-state memory model, making its output highly realistic and physics-aware.
Can Vidu AI be used outside of China?
Vidu AI is optimized for Chinese users and platforms, but it is expanding with broader language support. However, global usability may currently be limited compared to OpenAI and Google tools.
Which platform supports longer video durations—Sora AI, VEO 3, or Vidu AI?
Sora AI currently supports longer and more complex video sequences due to its large frame-to-frame memory buffer and autoregressive scene modeling.
Are these tools available for public use?
As of now, Sora AI is being tested with limited access, VEO 3 is not yet public but integrated into select Google services, and Vidu AI is semi-public in China through ModelScope and Bilibili AI hubs.
Subscribe To Our Newsletter
All © Copyright reserved by Accessible-Learning Hub
| Terms & Conditions
Knowledge is power. Learn with Us. 📚

