
Sora AI vs DALL-E 3: Features, Technical Details, and Applications
Sora AI vs DALL-E 3: A detailed comparison of OpenAI’s cutting-edge AI models for video and image generation. Explore their features, technical aspects, use cases, and how they shape the future of AI-driven creativity.
ARTIST/CREATIVITYAI ART TOOLSAI/FUTUREEDITOR/TOOLS
Sachin K Chaurasiya
3/6/20254 min read


Artificial Intelligence (AI) is rapidly transforming the creative industry, with tools like Sora AI and DALL-E 3 leading the revolution in AI-generated content. While Sora AI focuses on high-quality video generation, DALL-E 3 excels in AI-powered image creation. Both models push the boundaries of what AI can achieve in visual media, but how do they stack up against each other? Let’s explore their key differences, strengths, technical specifications, and ideal use cases.
What is Sora AI?
Sora AI, developed by OpenAI, is an advanced text-to-video model that can generate high-definition videos based on text prompts. Unlike previous AI models that struggled with realistic motion and coherence, Sora creates smooth, high-quality videos with remarkable detail.
Key Features
Text-to-Video Generation: Users can describe a scene, and Sora generates a video matching that description.
Consistent Character and Object Movements: Unlike older AI models, Sora ensures logical movement and consistency in video frames.
Multiple Styles & Realism: Capable of generating hyper-realistic, animated, or cinematic-style videos.
Extended Video Length: Compared to traditional AI video tools, Sora can produce longer videos with better motion control.
Physics and Object Interaction: Sora understands real-world physics, allowing for accurate simulations of motion, gravity, and object interactions.
Frame Rate and Resolution Control: Users can specify frame rates and resolutions, making it suitable for professional production.
Neural Rendering & Generative Adversarial Networks (GANs): Utilizes state-of-the-art GANs to create fluid motion and natural transitions.
Technical Aspects
Model Type: Deep Learning, Transformer-based architecture.
Training Data: Large-scale datasets of real-world video clips and simulations.
Processing Power: Requires high-end GPUs or cloud-based AI computing.
Output Formats: Supports MP4, MOV, and other standard video formats.
Limitations: Still struggles with highly complex human interactions and certain physics-based simulations.
Strengths
High-Quality Video Generation: Produces detailed and smooth motion sequences.
Realistic Object and Character Movements: Ensures continuity and natural physics.
Extended Video Length: Generates longer clips compared to older AI video models.
Multiple Styles & Cinematic Effects: Supports hyper-realistic, animated, and stylized videos.
Physics Simulation: Realistic object interaction enhances believability.
Ideal for Storytelling & Marketing: Useful for advertisements, animations, and educational content.
Weaknesses
High Computational Power Required: Needs powerful GPUs or cloud-based AI services.
Limited Control Over Specific Details: Struggles with fine-tuned character interactions.
Longer Processing Time: Video generation takes more time than image models.
Challenges in Complex Human Interactions: AI can sometimes misinterpret intricate body language.
Physics Can Be Imperfect: Occasionally produces unrealistic motion dynamics.
Use Cases
Content Creation: Ideal for filmmakers, social media influencers, and marketers.
Game Development & Animation: Useful for creating concept videos.
Education & Storytelling: Helps educators visualize lessons with AI-generated videos.
Scientific Simulations: Used in fields like physics, medical research, and climate modeling.


What is DALL-E 3?
DALL-E 3, also from OpenAI, is an AI-powered text-to-image model designed to generate high-quality, detailed images from text descriptions. DALL-E 3 improves upon its predecessors by better understanding context, composition, and finer details in images.
Key Features
High-Resolution Images: Capable of generating stunning images with fine details.
Better Text Interpretation: More accurate prompt understanding, reducing errors in composition.
Seamless Integration with ChatGPT: Can be used within ChatGPT for interactive AI-assisted image generation.
Artistic Freedom: Supports different artistic styles, from photorealistic to abstract and fantasy.
Inpainting & Outpainting: Allows users to edit images by filling in missing sections or extending them beyond their original borders.
Layered Image Processing: Generates images with better depth, texture, and lighting accuracy.
Vector and Raster Image Support: Can produce both high-quality raster images (JPEG, PNG) and vector-like elements for design purposes.
Technical Aspects
Model Type: Transformer-based generative model.
Training Data: Trained on large-scale annotated image datasets.
Processing Power: Requires high-performance GPUs and cloud AI processing.
Output Formats: Supports PNG, JPEG, and scalable formats for design applications.
Limitations: Struggles with rendering complex text inside images and may generate biased outputs due to training data limitations.
Strengths
High-Resolution Image Creation: Produces sharp, detailed, and vibrant images.
Better Text Understanding: Improved prompt comprehension for precise image outputs.
Supports Various Artistic Styles: From photorealistic to abstract and fantasy illustrations.
Seamless Integration with ChatGPT: Enhances interactive AI-assisted creativity.
Faster Processing Time: Generates images in seconds.
Useful for Graphic Design & Branding: Ideal for marketing, concept art, and digital content.
Weaknesses
Struggles with Text Rendering in Images: Sometimes produces garbled or incorrect text in images.
Limited Dynamic Motion Representation: Cannot create video or animated sequences.
Possible Bias in Image Outputs: May reflect biases present in its training data.
Inpainting & Outpainting Can Be Imperfect: Fails to blend edits smoothly in some cases.
Over-Reliance on Prompt Quality: Requires well-crafted prompts to achieve optimal results.
Use Cases
Graphic Design & Marketing: Helps businesses create eye-catching visuals.
Illustrations & Concept Art: Ideal for artists and designers.
E-commerce & Branding: Generates unique product visuals.
Architectural Visualization: Helps designers create concept images.
Medical Imaging & Scientific Visualization: Can assist in generating AI-assisted medical graphics.
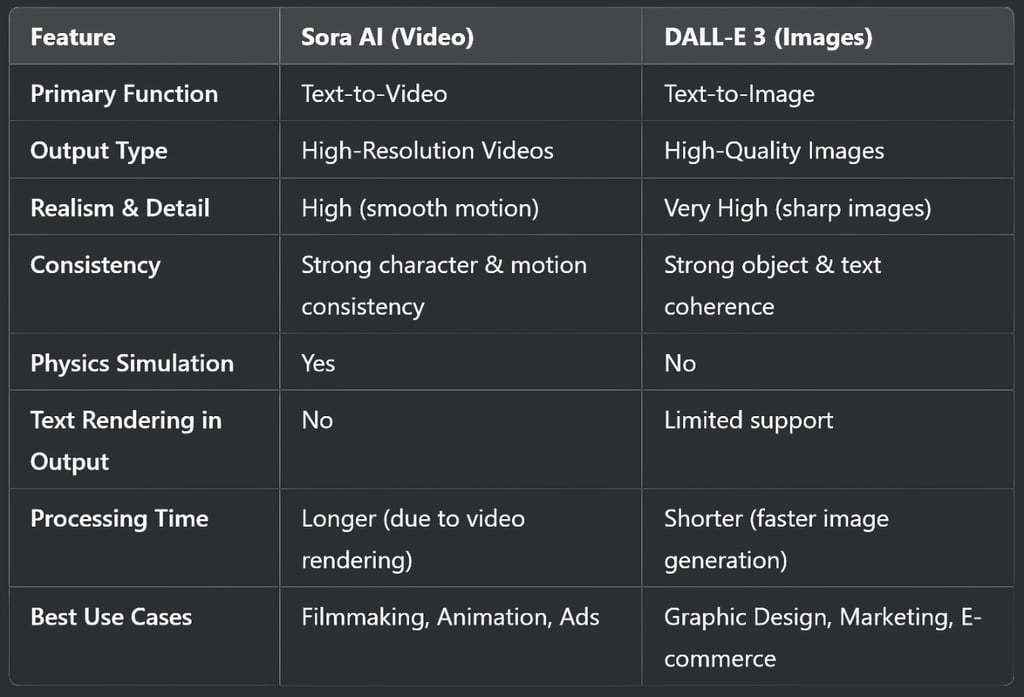
Which One Should You Use?
The choice between Sora AI and DALL-E 3 depends on your needs:
Choose Sora AI if you need AI-generated videos for storytelling, advertising, or animations.
Choose DALL-E 3 if you require high-quality images for branding, design, or creative projects.
If you work in multimedia content creation, combining both can create powerful visual storytelling experiences.
Both models are pushing the boundaries of AI creativity, and their applications are only expanding. If you’re a visual content creator, keeping an eye on both tools will help you stay ahead in this fast-evolving AI landscape.
While Sora AI and DALL-E 3 serve different purposes, they both represent the future of AI-driven creativity. As AI technology advances, we may even see a combination of both models, enabling users to create entire AI-generated multimedia projects seamlessly.
For now, whether you're creating a stunning digital painting or a short AI-generated film, OpenAI has a tool that can bring your vision to life.
Subscribe To Our Newsletter
All © Copyright reserved by Accessible-Learning Hub
| Terms & Conditions
Knowledge is power. Learn with Us. 📚

