
Perplexity Pro vs Andi AI: Research Depth vs Conversational Search
Explore an in-depth comparison of Perplexity Pro vs Andi AI, focusing on their core differences in research depth, conversational intelligence, technical architecture, and data handling. This detailed analysis breaks down how each platform approaches AI-driven search from multi-modal reasoning and citation-based results to lightweight semantic retrieval and privacy-first design. Ideal for researchers, developers, and everyday users deciding between accuracy and conversational speed.
AI ASSISTANTAI/FUTURECOMPANY/INDUSTRY
Sachin K Chaurasiya
11/27/20257 min read


In the evolving world of AI-driven search tools, Perplexity Pro and Andi AI stand out for their unique approaches to information retrieval. While both rely on large language models to generate intelligent answers, their philosophies differ sharply Perplexity Pro is built for research accuracy and depth, whereas Andi AI focuses on speed, simplicity, and conversational understanding.
Let’s explore both in detail to understand which one fits your needs best.
Perplexity Pro
Perplexity Pro is an advanced version of the popular AI search engine Perplexity AI, designed to serve as a research-grade assistant. It doesn’t just summarize answers; it explains, references, and verifies them.
Built with real-time web access and integration of multiple AI models, Perplexity Pro provides answers backed by citations and deep contextual insight. Professionals, students, and analysts use it to conduct multi-layered research without leaving the chat interface.
Key Highlights
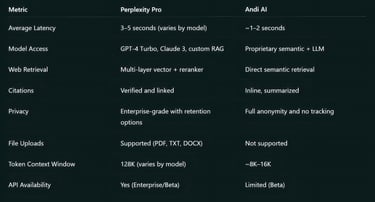
Model Access: Includes premium models such as GPT-4 Turbo and Claude, offering deeper reasoning and higher accuracy.
File Uploads: Allows users to upload PDFs or documents and ask contextual questions.
Citations & Transparency: Every answer is sourced, with clickable references.
Follow-up Threads: Lets users build ongoing research trails within a single conversation.
Pro Tier Benefits: Offers faster responses, unlimited queries, and higher token limits.
Perplexity Pro feels more like a research companion than a chatbot, ideal for people who need traceable, detailed, and source-based knowledge.
Practical Use Cases
Academic research and citation-based writing
Deep-dive analysis on complex topics
Market or competitive research
Professionals verifying data sources
Core Architecture and Model Foundation
Perplexity operates on a multi-model hybrid system integrating several LLM backbones, such as GPT-4 Turbo, Claude 3, and Perplexity’s own retrieval layer. The system performs retrieval-augmented generation (RAG), which combines live web search results with generative model reasoning.
Its pipeline functions in three steps:
Query Understanding: Uses semantic vector embeddings to interpret user intent and context.
Information Retrieval: Fetches relevant documents, snippets, or structured data from the web via its API-level search index.
Contextual Synthesis: Feeds retrieved data into the LLM for synthesis, summarization, and citation generation.
This layered design allows Perplexity to reconstruct context dynamically, ensuring the final answer is fresh, source-verified, and semantically aligned with the user’s intent.
Data Handling and Contextual Memory
Employs a context memory buffer, retaining user queries across sessions for follow-up analysis.
Utilizes query-chain reconstruction to build knowledge threads, allowing deeper exploration within one topic.
Incorporates document parsing and file indexing, letting users upload research papers or PDFs for contextual querying.
This makes Perplexity Pro behave like an AI-powered knowledge database, not just a chat interface. It’s particularly effective for iterative research, technical analysis, and knowledge synthesis.
Search Pipeline and Ranking Mechanism
Perplexity uses a multi-stage ranking mechanism:
Stage 1: Vector similarity search using text embeddings (based on OpenAI’s or custom dense embeddings).
Stage 2: Contextual reranking using transformer-based models.
Stage 3: Summarization with source scoring every document is assigned a reliability score before inclusion.
This ensures the system not only retrieves accurate sources but also weights them based on credibility and date relevance.
Technical Focus on Model Efficiency
Perplexity optimizes model use via adaptive compute allocation, automatically assigning smaller or larger models depending on query complexity. For example:
Short factual queries → GPT-3.5 or equivalent.
Research-heavy or multi-source questions → GPT-4 Turbo or Claude 3.
This multi-model elasticity balances cost, performance, and precision, making it powerful for long-form tasks.
Technical Privacy and Security Framework
Stores session logs and query data temporarily for service optimization.
Enterprise versions support data isolation and zero-retention modes for compliance.
Implements TLS encryption and allows API-level integration with controlled access tokens.
API and Developer Integration
Perplexity offers limited but growing API access for developers and enterprise users. Integrations allow:
Embedding the search engine into custom dashboards.
Automating multi-query research flows.
Interfacing with document databases for contextual querying.
Its API stack supports JSON outputs and customizable search parameters, ideal for workflow automation and research pipelines.

Andi AI
Andi AI redefines search by blending AI chat with web browsing. Instead of generating lengthy essays or research papers, it focuses on fast, conversational responses that feel natural and personal.
Andi is built around the idea of “humanized search,” meaning it talks to you like a person, filters noise, and gets to the point quickly. The platform’s major strength lies in its simplicity, privacy, and ad-free experience.
Key Highlights
Conversational Interface: Feels like chatting with a knowledgeable assistant rather than typing search queries.
Live Web Results: Combines LLM outputs with real-time web information.
Privacy Focused: No tracking, no ads, and no data profiling.
Fast and Lightweight: Optimized for instant answers, summaries, and fact-based replies.
Free Access: Available without subscription for most users.
Andi’s charm lies in its human-centered design, making it perfect for quick learning, general information, or creative brainstorming.
Practical Use Cases
Quick daily information and how-to questions
Conversational browsing without distractions
Fast summaries of trending topics
Users who value privacy and simplicity
Core Architecture and Model Foundation
Andi AI, on the other hand, focuses on lightweight AI retrieval and conversational fusion. Its backend uses a semantic search engine powered by dense passage retrieval (DPR) and embedding-based ranking, similar to how OpenAI’s embedding models or Cohere’s rerankers function.
Instead of chaining multiple large models, Andi fuses a single generative layer on top of its retrieval system, optimizing for speed and low latency. It leverages a context window limiter, ensuring concise, real-time responses without overextending token computation.
While it doesn’t run multi-model orchestration, Andi’s strength lies in its semantic accuracy and real-time data fusion, delivering conversational clarity with minimal computational overhead.
Data Handling and Contextual Memory
Operates with session-based ephemeral memory, meaning it remembers context within one chat but clears history for privacy.
Uses client-side caching to enhance response speed without storing personal data.
Applies session embeddings to maintain short-term continuity in conversation, ensuring fluid interactions.
This privacy-first approach means Andi never accumulates user profiles or long-term behavioral data, staying lightweight and secure.
Search Pipeline and Ranking Mechanism
Andi relies on a semantic retrieval ranker integrated with a direct web crawl pipeline. Instead of reranking documents in multiple stages, it:
Extracts top-ranked passages using semantic similarity.
Applies a lightweight fact-extraction model to identify claim-support pairs.
Summarizes results through a constrained generation model tuned for brevity.
The result is a fast, single-pass search loop that sacrifices deep verification for instant readability.
Technical Focus on Model Efficiency
Andi prioritizes low-latency inference. It uses quantized LLM models optimized for web-scale search and multi-threaded retrieval. The goal is to keep the round-trip time under two seconds.
By maintaining a smaller model footprint and relying more on retrieval rather than generation, Andi remains computationally lightweight and eco-efficient.
Technical Privacy and Security Framework
Fully ad-free and tracking-free, using privacy by design.
No cookies or third-party analytics that store identifiable information.
Queries are anonymized and non-persistent, deleted after processing.
API and Developer Integration
Andi’s API (currently in beta) is aimed at semantic search integration rather than full research pipelines. Developers can:
Query Andi’s search endpoint.
Receive summarized, conversational JSON responses.
Integrate lightweight AI search into chatbots or apps with minimal latency.
Andi’s open approach makes it appealing for developers building personal search assistants or privacy-centered apps.

Research Depth vs Conversational Ease
The core difference between Perplexity Pro and Andi AI lies in their purpose:
Perplexity Pro emphasizes depth, accuracy, and traceability, suitable for research professionals and academics.
Andi AI focuses on conversational flow and simplicity, ideal for daily use or fast fact-checking.
Where Perplexity analyzes multiple documents to form a detailed, sourced answer, Andi summarizes information conversationally without overloading the user with citations.
Performance and Speed
Perplexity Pro uses more sophisticated reasoning models, so its processing may take slightly longer, especially for in-depth questions. However, its responses are typically more accurate and verifiable.
Andi AI, on the other hand, prioritizes speed and readability. Its real-time integration makes it incredibly responsive, offering short, digestible summaries in seconds.
If you value efficiency, Andi wins. If you value precision, Perplexity takes the lead.
Pricing and Accessibility
Perplexity Pro is subscription-based, with plans around $20/month, giving users access to advanced features, premium models, and enhanced limits.
Andi AI is completely free, maintaining an ad-free experience supported by partnerships and lightweight infrastructure.
For professionals, the cost of Perplexity Pro is justified by its capabilities. For casual users, Andi provides a generous and private alternative.
Future Development Outlook
Perplexity Pro is expected to evolve into a multi-agent research ecosystem, integrating document comparison, citation validation, and automated referencing. It’s moving toward enterprise intelligence systems that blend human oversight with AI synthesis.
Andi AI is focused on scalable conversational search, with emphasis on lightweight LLM integration, real-time web updates, and API availability for independent developers.
Both represent different visions of AI search, with Perplexity as the research-grade oracle and Andi as the conversational navigator.
Technically speaking, Perplexity Pro leads in research sophistication with retrieval orchestration, model elasticity, and contextual data synthesis. It’s built for analysts, professionals, and researchers who demand precision, multi-source validation, and long-context reasoning.
Andi AI, in contrast, excels in speed, simplicity, and ethical design. Its minimalist AI stack prioritizes fast information delivery and strong user privacy.
If you value technical rigor and deep context understanding, Perplexity Pro is your platform. If you prefer privacy-first, real-time conversational intelligence, Andi AI delivers a more approachable and efficient experience.


FAQ's
Q: What is the main difference between Perplexity Pro and Andi AI?
Perplexity Pro focuses on deep, source-backed research using multi-model AI and citation tracking, while Andi AI delivers fast, conversational answers designed for everyday search and privacy-first experiences.
Q: Is Perplexity Pro better for professional or academic use?
Yes. Perplexity Pro is ideal for researchers, analysts, and professionals who need traceable information, document uploads, and advanced AI reasoning. It supports citations, context retention, and file-based querying, making it a strong research companion.
Q: Is Andi AI free to use?
Yes, Andi AI is completely free, with no ads or tracking. It’s built for users who want quick, accurate, and conversational answers without compromising privacy.
Q: Can I upload files or PDFs in Andi AI like in Perplexity Pro?
No. Andi AI currently doesn’t support file uploads or document analysis. Perplexity Pro, however, allows file uploads, enabling users to query within their own documents for research-based tasks.
Q: Which AI tool gives faster responses?
Andi AI generally provides faster responses because it uses a lightweight retrieval-based model optimized for speed. Perplexity Pro, while slightly slower, offers greater reasoning accuracy and deeper synthesis.
Q: Does Perplexity Pro ensure data privacy?
Yes. Perplexity Pro uses encrypted connections and offers enterprise-level privacy controls, especially for business and research accounts. However, Andi AI goes a step further with full anonymity and no data storage.
Q: Which one should I choose for my daily workflow?
Choose Perplexity Pro if your work involves research, academic writing, or report generation. Choose Andi AI if you need a quick, conversational search engine for learning, daily queries, or creative exploration.
Subscribe To Our Newsletter
All © Copyright reserved by Accessible-Learning Hub
| Terms & Conditions
Knowledge is power. Learn with Us. 📚

