
OpenCLIP, ALIGN, and MetaCLIP Compared: Which AI Model Leads the Future?
Discover the key differences between OpenCLIP, ALIGN, and MetaCLIP—three advanced vision-language models shaping the future of AI. Explore their architectures, capabilities, real-world applications, and performance benchmarks in this in-depth comparison
AI/FUTUREEDITOR/TOOLSCOMPANY/INDUSTRYPROGRAMMING
Sachin K Chaurasiya
2/22/20254 min read


With the rapid evolution of AI-driven image and text understanding, models like OpenCLIP, ALIGN, and MetaCLIP have emerged as powerful tools for zero-shot learning and multimodal representation learning. These models bridge the gap between images and textual descriptions, revolutionizing applications in content generation, search engines, and AI-based analytics.
This article provides an in-depth comparative analysis of OpenCLIP, ALIGN, and MetaCLIP, exploring their architectures, capabilities, performance, and real-world applications.
OpenCLIP
OpenCLIP (Open Contrastive Language-Image Pretraining) is an open-source version of OpenAI's CLIP model, designed to provide publicly accessible, scalable, and reproducible training of contrastive learning-based vision-language models.
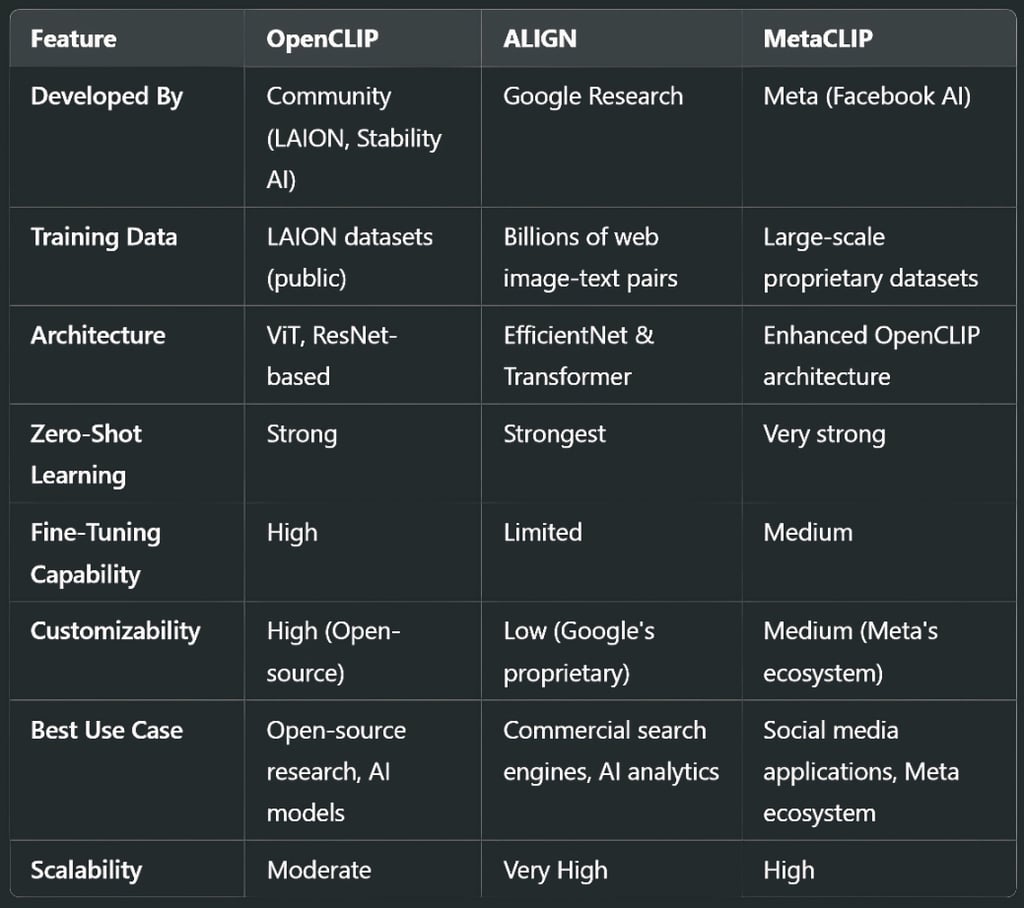
Developed by: LAION & Stability AI (Community-driven)
Key Features
Open-source and customizable
Trained on diverse large-scale datasets (e.g., LAION-5B)
Supports multiple architectures (ViT, ResNet, etc.)
Efficient zero-shot learning capabilities
Can be fine-tuned for specific industry applications
Suitable for low-resource AI startups and academic research
Technical Information
Training Data: LAION-5B dataset (web-scale, publicly available)
Architecture: Supports ViT, ResNet, and hybrid vision-language models
Training Method: Contrastive learning via text-image pairs
Fine-tuning: High flexibility due to open-source nature
Deployment: Requires manual optimization for industry-level deployment
Strengths
Open-source & customizable: Researchers and developers can fine-tune models for specific applications.
Supports multiple architectures: Works with Vision Transformers (ViT), ResNet, and other backbones.
Scalable with diverse datasets: Uses LAION-5B, allowing broader generalization.
Fine-tuning capabilities: Easier adaptation for niche AI applications.
Weaknesses
Computationally expensive: Requires significant GPU resources for large-scale training.
Lower real-world optimization: May not perform as efficiently as proprietary models like ALIGN in web-scale deployments.
Noisy dataset impact: LAION-5B is community-curated, leading to possible biases in training data.
Performance & Real-World Applications
Ideal for academic research and AI startups due to its open-source nature.
Used in image search engines and AI-powered content moderation.
Customizable for specialized AI models.
Adaptable for small-scale and enterprise-level AI applications.
Suitable for AI-driven medical image analysis and document processing.
Use Cases
AI research & academia
Open-source AI projects
AI-driven medical image analysis
Custom AI-powered content moderation systems
Niche AI models in small startups


ALIGN
ALIGN (Autonomous Learning of Image Next to Text) is a vision-language model developed by Google Research, designed for large-scale multimodal representation learning without extensive labeled datasets.
Developed by: Google Research
Key Features
Trained on billions of noisy image-text pairs from the web
Strong cross-modal representations for retrieval and classification
Uses EfficientNet as the vision backbone and Transformer-based text encoders
Excels in zero-shot classification and retrieval tasks
Designed for web-scale deployment in commercial applications
Integrated into Google’s AI ecosystem for better search and recommendation algorithms
Technical Information
Training Data: Billions of image-text pairs scraped from the web
Architecture: EfficientNet as vision encoder + Transformer-based text encoder
Training Method: Large-scale contrastive learning (self-supervised)
Fine-tuning: Limited outside Google’s ecosystem
Deployment: Web-scale AI models with proprietary optimization
Strengths
Best zero-shot learning performance: Pretrained on billions of noisy image-text pairs from the web.
Highly scalable: Optimized for Google’s AI-powered search and recommendation systems.
Strong generalization: Efficient in handling web-based, real-world data.
Optimized architecture: Uses EfficientNet for vision and transformer-based encoders for text.
Weaknesses
Not open-source: Difficult to modify or fine-tune for specific applications outside Google’s ecosystem.
Noisy data dependency: Uses web-crawled datasets, which may introduce biases.
Limited accessibility: Available only within Google’s AI research and commercial products.
Performance & Real-World Applications
Deployed in Google Search, Google Lens, and YouTube AI for content understanding.
Excels in handling noisy datasets, making it robust for real-world web applications.
Strongest zero-shot learning among the three models.
Utilized for e-commerce product recommendation systems.
Key in real-time AI-based language translation models.
Use Cases
AI-powered search engines (Google Search, Google Lens)
E-commerce recommendation systems
Automated content tagging for large-scale platforms
Real-time AI-based language translation
AI-driven news categorization and filtering


MetaCLIP
MetaCLIP is Meta’s (Facebook AI) adaptation of contrastive learning for vision-language tasks, aimed at advancing AI's understanding of images and their textual descriptions.
Developed by: Meta (Facebook AI)
Key Features
Optimized for high-performance vision-language alignment
Built upon OpenCLIP and enhanced for social media-scale datasets
Advanced feature extraction techniques for better generalization
Strong zero-shot and few-shot learning capabilities
Specifically optimized for content moderation, tagging, and recommendation algorithms on social media platforms
Seamless integration into Meta’s metaverse and AR/VR projects
Technical Information
Training Data: Meta’s proprietary social media dataset
Architecture: Enhanced OpenCLIP-based vision-language model
Training Method: Contrastive learning with advanced feature extraction
Fine-tuning: Optimized for social media, limited for external users
Deployment: Integrated into Meta’s AI-driven applications
Strengths
Optimized for social media AI applications: Designed for Meta’s platforms like Facebook, Instagram, and Metaverse.
Advanced feature extraction: Stronger generalization in social media content moderation.
Fine-tuned for AR/VR: Supports AI-driven applications in Metaverse and augmented reality (AR).
Enhanced OpenCLIP foundation: Improves upon OpenCLIP with Meta’s proprietary optimizations.
Weaknesses
Limited accessibility: Not open-source, restricted to Meta’s ecosystem.
Bias in social media datasets: Trained on Meta-specific datasets, making it less versatile for external applications.
Less efficient for search engines: Compared to ALIGN, it lacks large-scale web search capabilities.
Performance & Real-World Applications
Meta’s edge in social media AI applications, AR, and VR.
Improves content recommendations, image tagging, and AI moderation on platforms like Facebook and Instagram.
Integrated into Metaverse and AI-driven virtual environments.
Supports AI-driven advertisement targeting and personalization.
Used in Meta's AI research for deepfake detection and security applications.
Use Cases
Content moderation & AI-driven filtering on Facebook and Instagram
AI-powered social media recommendation systems
Metaverse & VR applications for interactive AI
Deepfake detection & security applications
AI-driven advertisement targeting
Which Model Should You Choose?
For AI research & customization → OpenCLIP (Open-source, flexible, and community-driven)
For large-scale AI-powered search & classification → ALIGN (Best for commercial AI and search engines)
For social media AI & content understanding → MetaCLIP (Optimized for Meta’s ecosystem)
For AI-powered creative applications & automation → OpenCLIP or MetaCLIP
For AI-driven recommendation engines → ALIGN or MetaCLIP
Each of these models—OpenCLIP, ALIGN, and MetaCLIP—brings unique strengths to the field of vision-language AI. OpenCLIP leads in open-source flexibility, ALIGN dominates large-scale multimodal learning, and MetaCLIP enhances AI-driven social media experiences.
As AI continues to advance, these models will evolve, offering better performance and more sophisticated real-world applications. Whether you're a researcher, a developer, or a business looking for AI-driven solutions, selecting the right model depends on your specific needs and goals.
The future of multimodal AI is promising, with continuous improvements in efficiency, adaptability, and interpretability. Keeping up with these advancements will be crucial for businesses, researchers, and AI enthusiasts alike.
Subscribe To Our Newsletter
All © Copyright reserved by Accessible-Learning Hub
| Terms & Conditions
Knowledge is power. Learn with Us. 📚

