
MetaCLIP vs OpenCLIP: Which Vision-Language Model is Better?
Explore the in-depth comparison between OpenCLIP vs MetaCLIP, two leading vision-language models. Understand their architecture, training methodologies, performance, and real-world applications. Learn which model suits your needs, whether for open-source AI research or large-scale industry applications.
AI ASSISTANTCOMPANY/INDUSTRYAI/FUTUREEDUCATION/KNOWLEDGE
Sachin K Chaurasiya
2/19/20255 min read


The field of vision-language models has witnessed rapid advancements, and CLIP-based architectures have become central to this revolution. OpenCLIP and MetaCLIP are two major implementations of this technology, each with its unique approach, strengths, and use cases. In this article, we will explore these two models in-depth, comparing their architecture, training methodologies, performance, and real-world applications.
What is OpenCLIP?
OpenCLIP is an open-source implementation of OpenAI’s CLIP (Contrastive Language-Image Pretraining) model. It was developed to provide a reproducible, scalable, and community-driven alternative to proprietary implementations. OpenCLIP aims to democratize vision-language learning by allowing researchers to train and fine-tune models on diverse datasets.
Key Features
Open-source and community-driven—Unlike OpenAI’s CLIP, OpenCLIP allows modifications, making it widely accessible.
Scalability—Supports training on large-scale datasets, improving model accuracy and adaptability.
Versatile foundation model—Can be fine-tuned for diverse tasks like zero-shot image classification, retrieval, and captioning.
Pretrained models—Come with multiple pretrained versions on different datasets, such as LAION-400M, enabling researchers to experiment with various architectures.
Supports multiple architectures—includes implementations with Vision Transformer (ViT), ResNet, and other architectures for diverse performance trade-offs.
Training Methodologies
Relies on large-scale, publicly available image-text datasets like LAION-400M.
Trains on a contrastive learning objective, maximizing the similarity between corresponding text and image embeddings.
Uses transformer-based text encoders and ResNet/ViT (Vision Transformer) image encoders.
Provides community-driven improvements and additional architectures.
Supports multiple loss functions, including cross-entropy and contrastive loss, for diverse learning paradigms.
Strengths
Open-source & Community-Driven: Freely accessible and modifiable, enabling researchers and developers to contribute and improve it.
Scalability: Can be trained on diverse public datasets, making it highly adaptable.
Versatile Model Architectures: Supports multiple architectures like Vision Transformers (ViT) and ResNet, giving users flexibility.
Fine-Tuning Capabilities: Users can fine-tune the model for specific applications, unlike proprietary models with limited access.
Transparent Training Process: Since it is open-source, the training methodologies, dataset usage, and implementation details are publicly available.
Weaknesses
Dataset Limitations: Relies on public datasets like LAION-400M, which may have inconsistencies, biases, and lower-quality data compared to Meta’s curated datasets.
Computationally Intensive: Training from scratch requires significant GPU/TPU resources, making it less accessible to smaller research groups.
Performance Trade-offs: While competitive, OpenCLIP may not match MetaCLIP’s performance in real-world tasks due to dataset constraints.
Lack of Proprietary Optimizations: Does not benefit from Meta’s large-scale AI infrastructure and proprietary enhancements.
Technical Information & Architecture
Training Approach: Uses contrastive learning with large-scale text-image pairs from public datasets (e.g., LAION-400M).
Backbone Architectures: Supports multiple architectures, including Vision Transformers (ViT) and ResNet-based models.
Text Encoder: Uses a transformer-based architecture similar to GPT for encoding textual data.
Image Encoder: Uses ViT or ResNet to extract image features and align them with text embeddings.
Loss Function: Employs contrastive loss to maximize the similarity between matching text-image embeddings.
Zero-Shot Learning: Allows classification without explicit training on specific categories by learning general representations.
Use Cases
Academic research in vision-language modeling.
Open-source AI projects that require interpretable and flexible multimodal models.
Companies are looking for AI solutions without relying on proprietary Meta tools.
Fine-tuning for niche applications in healthcare, education, and creative industries.


What is MetaCLIP?
MetaCLIP is Meta’s approach to vision-language pretraining. Unlike OpenCLIP, which is a community-driven initiative, MetaCLIP is developed by Meta (formerly Facebook) and optimized for large-scale multimodal learning. It is designed for efficiency, leveraging Meta’s advanced AI infrastructure to enhance retrieval-based and generative applications.
Key Features
Optimized for efficiency—Uses Meta’s large-scale AI infrastructure for improved training speed and lower computational costs.
Proprietary dataset usage—MetaCLIP benefits from Meta’s proprietary datasets, enhancing performance in real-world applications.
Strong multimodal integration—Designed to integrate with Meta’s broader AI ecosystem, including image generation, video understanding, and augmented reality.
Targeted applications—Used primarily in Meta’s products for content moderation, visual search, and personalized recommendations.
Utilizes advanced transformer architectures—Incorporates Meta’s proprietary modifications to transformer models for enhanced accuracy and efficiency.
Training Methodologies
Trained on proprietary datasets curated by Meta, ensuring higher-quality and diverse data.
Optimized with Meta’s high-performance computing infrastructure, reducing training costs.
Uses advanced transformer architectures and Meta’s internal optimizations for enhanced accuracy and efficiency.
Specifically designed for seamless integration with Meta’s AI-powered applications.
Implements dynamic contrastive learning strategies to improve contextual embeddings.
Strengths
Optimized for Large-Scale Applications: Uses Meta’s advanced AI infrastructure, making it highly efficient in real-world deployments.
Superior Performance: Access to high-quality proprietary datasets enhances its performance in tasks like visual search and content moderation.
Integration with Meta Ecosystem: Works seamlessly with Meta's AI-driven platforms, including Facebook, Instagram, and AR/VR applications.
Efficient Training & Inference: MetaCLIP’s optimized transformer architecture ensures faster inference and lower latency.
Better Generalization in Proprietary Use Cases: Performs well in Meta’s targeted applications due to dataset quality and proprietary training techniques.
Weaknesses
Proprietary & Closed-Source: Not accessible to external researchers, limiting transparency and modification capabilities.
Limited Customization: Unlike OpenCLIP, users outside Meta cannot fine-tune or adapt the model for specific needs.
Dataset Dependency: While proprietary datasets provide an advantage, they are not available for public use, making model evaluation difficult outside Meta’s ecosystem.
Bias & Ethical Concerns: Since it is trained on Meta’s datasets, it may reflect biases present in social media content and Meta’s curation strategies.
Technical Information & Architecture
Training Approach: Uses contrastive learning but leverages Meta’s proprietary datasets, ensuring better data quality and diversity.
Backbone Architectures: Implements advanced transformer modifications for better efficiency and scalability.
Text Encoder: Utilizes Meta-optimized transformer models for improved contextual understanding.
Image Encoder: Incorporates proprietary enhancements to transformer-based vision models for superior feature extraction.
Optimization Techniques: Uses Meta’s large-scale AI infrastructure, optimizing model training with distributed learning strategies.
Application-Specific Customization: Tailored for Meta’s AI products, enabling advanced multimodal content understanding.
Use Cases
Meta’s AI-driven platforms, including Facebook, Instagram, and WhatsApp.
Content moderation and filtering to identify harmful or misleading images.
Visual search and recommendation systems in e-commerce and advertising.
Augmented reality (AR) and virtual reality (VR) applications for Meta’s metaverse projects.
Architecture Comparison
Both OpenCLIP and MetaCLIP follow the CLIP paradigm, where images and text are encoded into a shared embedding space. However, there are key differences in their architectures:
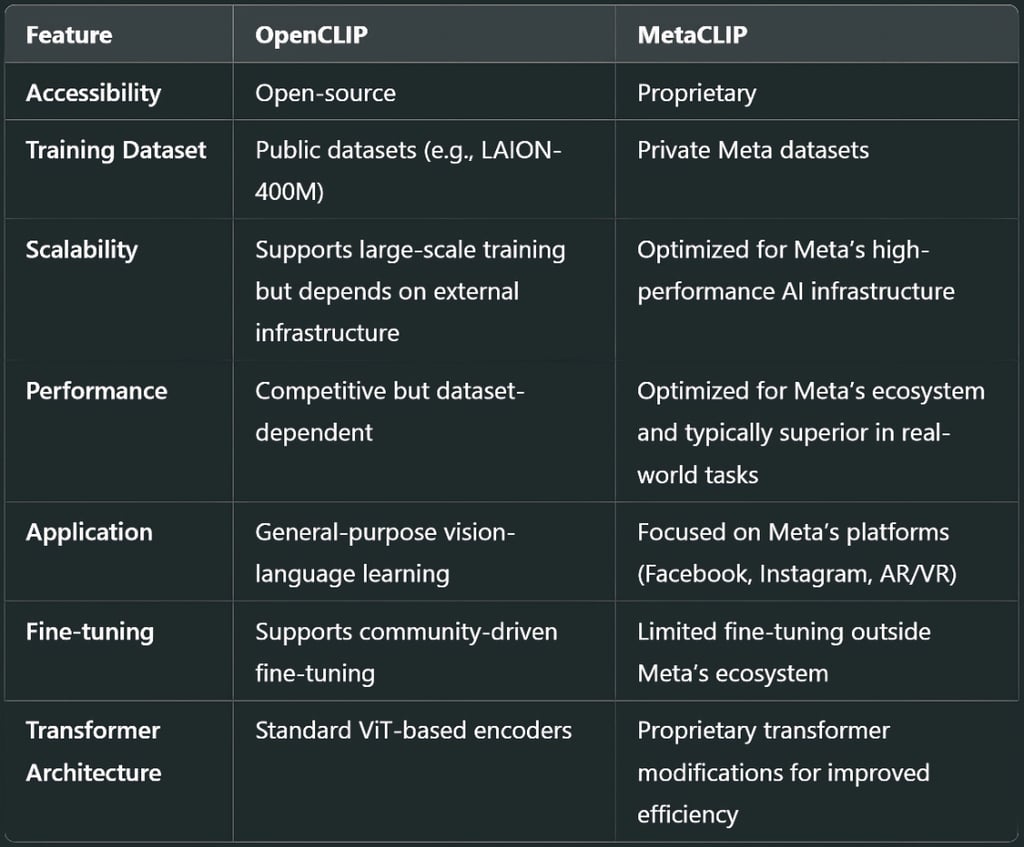
Performance and Accuracy
MetaCLIP generally performs better in real-world applications due to its access to high-quality proprietary datasets and extensive computational resources. However, OpenCLIP offers competitive performance, particularly when fine-tuned with high-quality datasets.
Benchmarks show that
MetaCLIP outperforms OpenCLIP in retrieval tasks due to its enhanced dataset curation and model optimizations.
OpenCLIP is more flexible and can be fine-tuned for specialized tasks by researchers outside Meta’s ecosystem.
Zero-shot learning accuracy is comparable, though MetaCLIP holds an edge in tasks involving complex multimodal reasoning.
Latency and inference speed—MetaCLIP achieves faster inference due to its optimized transformer-based architecture.
Future Prospects
OpenCLIP may see further improvements with community-driven research and access to larger datasets, enhancing its ability to compete with proprietary models.
MetaCLIP will likely integrate more deeply with Meta’s AI advancements, including real-time multimodal processing and generative AI features.
The increasing use of synthetic data for training could benefit both models, improving generalization and reducing biases.
Both models may evolve to support video-text learning, enabling more advanced applications in content understanding and generation.
Hardware acceleration—Expect more optimizations for GPU/TPU acceleration, reducing computational overhead.
Which One Should You Choose?
For open-source flexibility, transparency, and customization, OpenCLIP is the better option.
For performance-optimized, large-scale applications within Meta’s ecosystem, MetaCLIP is the ideal choice.
OpenCLIP and MetaCLIP represent two distinct approaches to vision-language learning. OpenCLIP, with its open-source nature, empowers the AI community to build and refine multimodal models. On the other hand, MetaCLIP, backed by Meta’s proprietary resources, excels in large-scale real-world applications.
Subscribe To Our Newsletter
All © Copyright reserved by Accessible-Learning Hub
| Terms & Conditions
Knowledge is power. Learn with Us. 📚

