
DreamBooth vs LoRA vs Textual Inversion: Which One is Best for Fine-Tuning AI Models?
DreamBooth vs LoRA vs Textual Inversion – Which fine-tuning technique is best for AI image generation? Discover their differences, advantages, limitations, and best use cases to choose the right method for your creative needs.
AI/FUTUREARTIST/CREATIVITYAI ART TOOLSEDUCATION/KNOWLEDGE
Sachin K Chaurasiya
4/8/20255 min read


In the ever-evolving world of AI image generation, customization is key. Whether you're a digital artist, a researcher, or a business looking to personalize AI-generated content, fine-tuning models is essential. Among the most popular techniques for customizing AI image generators like Stable Diffusion and other transformer-based models are DreamBooth, LoRA (Low-Rank Adaptation), and Textual Inversion. Each method has its unique strengths and weaknesses, making it crucial to choose the right approach based on your specific needs.
In this article, we'll break down DreamBooth vs LoRA vs Textual Inversion, exploring how they work, their advantages, limitations, and ideal use cases. Let’s dive in!
What is DreamBooth?
DreamBooth, developed by Google Research, is a fine-tuning technique that allows an AI model to learn a specific subject from a small set of images (3-5 samples) and generate new images featuring that subject in various contexts. It is commonly used with Stable Diffusion and Imagen models.
How DreamBooth Works
Pretraining the Model: The AI model is initially trained on a large dataset to understand general visual concepts.
Subject Encoding: You provide a handful of images of a subject (e.g., a pet, a person, or an object). The model learns to associate a unique identifier (e.g., sks_person) with that subject.
Fine-Tuning: The model is trained further to recognize the fine details of the subject while preserving its pre-trained knowledge.
Prompt-Based Generation: Once trained, the model can generate new images of the subject in different styles, environments, or settings using textual prompts.
Advantages
✅ Highly Personalized: Can fine-tune a model to recognize and reproduce highly detailed subjects accurately.
✅ Few Samples Needed: Requires only a few images to train.
✅ Flexible Use Cases: Can generate images with specific themes or settings.
✅ Integrates with Text Prompts: Can be used alongside prompt-based AI generation.
✅ Retains Realism: Produces high-quality and realistic outputs that resemble the original subject.
Limitations
❌ Computationally Expensive: Requires a lot of GPU power (minimum 16GB VRAM, preferably more) for training.
❌ Longer Training Time: Can take hours to train effectively, depending on dataset size and computing power.
❌ Overfitting Risks: Can cause the model to forget other knowledge (catastrophic forgetting) if not trained properly.
❌ File Size: The trained model can become quite large (several GBs), making it harder to share or deploy.
Best For
Artists and photographers who want AI-generated images in their unique style.
Personalizing AI-generated avatars, portraits, or branding images.
Generating consistent AI visuals of specific characters or mascots.


What is LoRA (Low-Rank Adaptation)?
LoRA is a lightweight fine-tuning technique designed to efficiently adapt large-scale AI models using significantly fewer resources. It modifies only a small subset of model parameters rather than retraining the entire model.
How LoRA Works
Injecting Low-Rank Matrices: Instead of updating all parameters, LoRA inserts low-rank matrices into specific layers of the model.
Weight Reduction: The model learns new information through these small matrices rather than modifying the core model weights.
Fast Training and Deployment: The LoRA module is added dynamically and can be loaded when needed, reducing computational costs.
Parameter-Efficient Tuning: Only a fraction of the parameters are modified, preserving the general knowledge of the base model.
Advantages
✅ Low Computational Cost: Requires significantly less GPU power compared to DreamBooth.
✅ Faster Training: Takes minutes instead of hours to fine-tune.
✅ Modular and Reusable: Can be stacked with other LoRA models without overwriting core AI knowledge.
✅ Lower VRAM Requirement: Can work on GPUs with 8GB VRAM or even less.
✅ Preserves Base Model Knowledge: Unlike DreamBooth, it does not cause catastrophic forgetting.
Limitations
❌ Limited Scope: Works best for small changes rather than drastic transformations.
❌ Lower Personalization: Less effective for learning highly detailed or unique subjects.
❌ Dependent on Base Model: Performance depends on the base AI model’s capabilities.
Best For
Enhancing AI-generated art with slight modifications or stylistic tweaks.
Adding new features to an AI model without retraining it from scratch.
Customizing AI-generated text-to-image models with minimal computational resources.
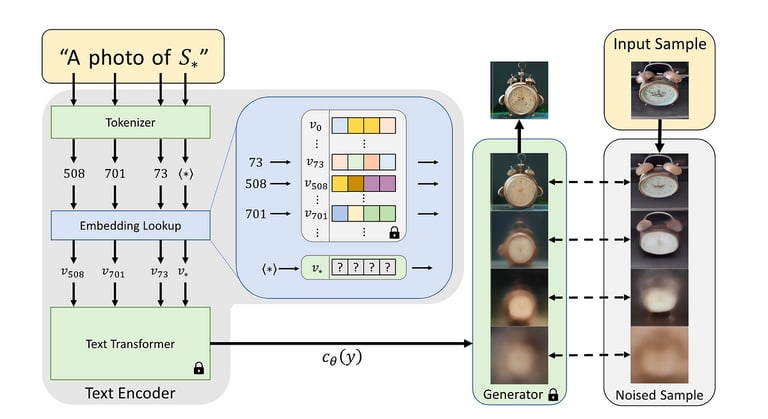
What is Textual Inversion?
Textual Inversion is a prompt-based fine-tuning technique that teaches an AI model new concepts by associating them with a unique textual token.
How Textual Inversion Works
Concept Encoding: A few images of a new subject or style are provided.
Vector Training: The AI model learns to associate a custom textual token (e.g., <new_subject>) with the new concept.
Text-Based Prompting: You can then use this token in text prompts to generate images featuring the learned subject.
Advantages
✅ Efficient and Lightweight: Doesn't require modifying the model weights.
✅ Works Well with Prompts: Easily integrates with text-based image generation models.
✅ Fast Training: Can be trained in a short time with limited computational resources.
✅ Portable & Shareable: Unlike DreamBooth, the learned embeddings are small files (<100KB), making them easy to distribute.
✅ Preserves Model Integrity: Doesn't interfere with the base model’s knowledge.
Limitations
❌ Lower Detail Transfer: Struggles with capturing fine details compared to DreamBooth.
❌ Dependent on Prompt Engineering: Requires carefully crafted text prompts to generate desired outputs.
❌ Limited Customization: Cannot deeply alter the AI model’s knowledge base.
Best For
Users who want a lightweight way to introduce new styles or subjects into AI-generated images.
Artists are looking for an easy way to integrate unique elements into their AI art.
People who want AI-generated images of specific subjects without retraining an entire model.


FAQs
Which method is best for fine-tuning AI image models?
If you need highly personalized, detailed outputs, DreamBooth is the best choice.
If you want a lightweight and efficient tuning method, LoRA is ideal.
If you prefer prompt-based fine-tuning with minimal computation, Textual Inversion is the way to go.
Does DreamBooth require a powerful GPU?
Yes, DreamBooth is resource-intensive and typically requires a high-end GPU with at least 16GB VRAM for effective training.
Can LoRA and Textual Inversion be used together?
Yes! LoRA can be stacked with Textual Inversion to enhance AI model customization without overwriting base knowledge.
Which technique is best for generating AI avatars?
DreamBooth is the best choice for consistent and high-quality AI-generated avatars.
Is Textual Inversion suitable for detailed subject replication?
No, Textual Inversion is better for learning styles or abstract concepts rather than precise subject replication.
Can I use LoRA on consumer-grade GPUs?
Yes! LoRA is optimized for lower VRAM (as low as 8GB VRAM), making it ideal for most consumer GPUs.
How much time does each method take to fine-tune?
DreamBooth: Several hours (depending on dataset size and GPU power).
LoRA: Few minutes to an hour.
Textual Inversion: Less than an hour.
Subscribe To Our Newsletter
All © Copyright reserved by Accessible-Learning Hub
| Terms & Conditions
Knowledge is power. Learn with Us. 📚

