
DreamBooth vs LoRA vs Textual Inversion: A Complete Guide to AI Fine-Tuning for Personalized Image Generation
Explore the key differences between DreamBooth, LoRA, and Textual Inversion, three advanced AI fine-tuning methods used in Stable Diffusion. Learn how each technique personalizes AI art, their technical strengths, training efficiency, and how to combine them for professional-grade, customized image generation.
AI/FUTURECOMPANY/INDUSTRYEDITOR/TOOLSAI ART TOOLS
Sachin K Chaurasiya
11/14/202511 min read
AI art is evolving fast, but true personalization capturing your face, your style, or your brand’s visual identity needs more than prompt engineering. That’s where fine-tuning techniques like DreamBooth, LoRA, and Textual Inversion come into play.
Each method offers a different way to teach AI models new concepts without retraining them from scratch. This guide will break down how they work, where they shine, and how to combine them for professional-level results.
Why Fine-Tuning Matters
Modern text-to-image models like Stable Diffusion, SDXL, and Flux can generate stunning results from simple prompts. But out of the box, they can’t “understand” your personal look, your original character, or your unique brand style.
Fine-tuning fixes that by allowing you to:
Teach the model specific subjects, faces, or objects
Embed artistic styles or techniques
Preserve creative consistency across multiple artworks
Recreate exact poses or identities across different contexts
Without fine-tuning, AI art remains generic. With it, AI becomes a personal creative assistant.
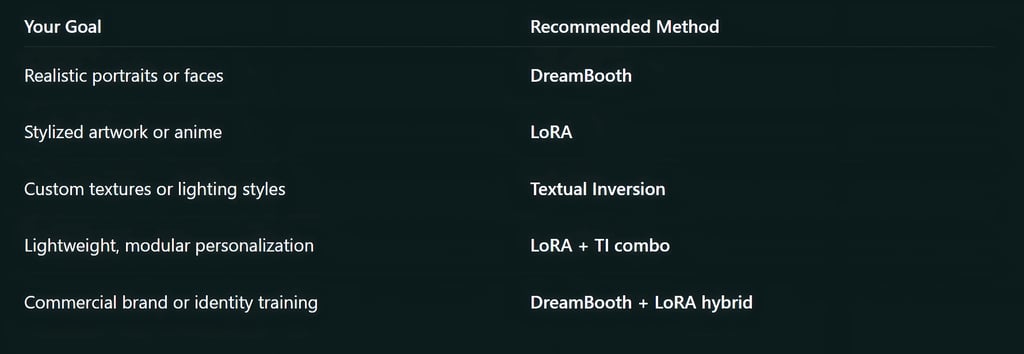
DreamBooth: Precision and Photorealism at a Cost
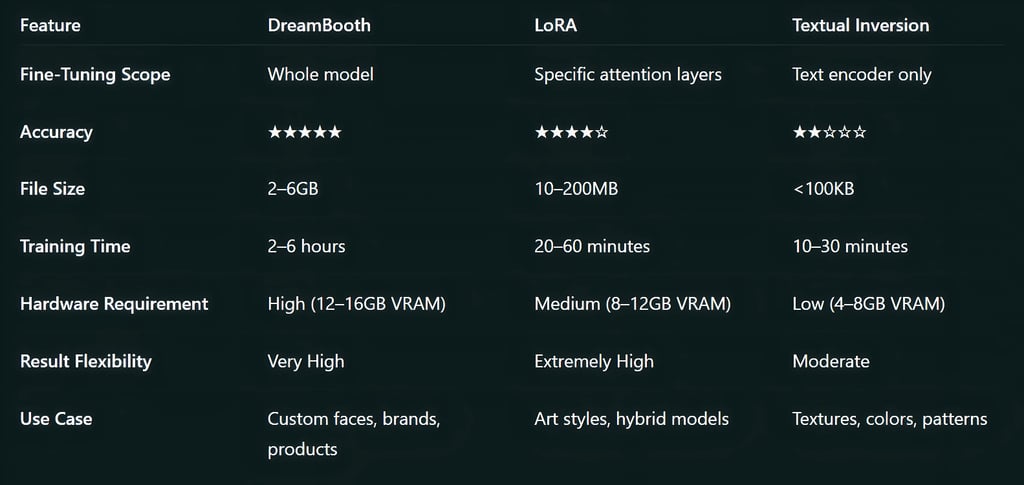
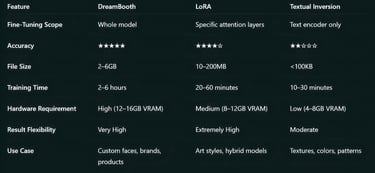
DreamBooth, developed by Google Research, is the most detailed and accurate personalization technique. It fine-tunes the entire diffusion model using a small image dataset, often 4 to 10 photos of a person or object.
How It Works
You provide reference images and define a special token (e.g., “sks man”).
The model learns to associate that token with your subject’s appearance and traits.
It can then generate your subject in new poses, outfits, or settings using natural prompts.
Advanced Technical Points
Works best on models like Stable Diffusion 1.5 or SDXL Base.
Uses class images (regularization) to avoid “overfitting.”
Training parameters such as learning rate (2e-6) and gradient accumulation are critical.
Typically requires 12–16GB VRAM and 2–6 hours for stable results.
Advantages
Highly accurate in preserving facial structure and fine details.
Generates subjects in multiple styles and environments.
Best suited for commercial portraiture, product branding, and creative agencies.
Limitations
Large model size (2–6GB).
Slower training and higher GPU demand.
Harder to distribute or merge with other models.
Pro Tip
To reduce overtraining, use diverse backgrounds and lighting. Avoid repeating similar images variety improves adaptability.

LoRA: The Perfect Blend of Speed, Flexibility, and Quality
LoRA (Low-Rank Adaptation) is a more efficient fine-tuning approach that modifies specific layers of the model rather than the entire network. This keeps file sizes small and makes it easy to combine multiple styles.
How It Works
LoRA adds small “adapter layers” to the model’s attention mechanisms. These layers learn new styles or subjects while the main model stays untouched. When you load a LoRA, it temporarily overlays your fine-tuning without overwriting the base model.
Technical Highlights
File size: 10–200MB.
Training time: 20–60 minutes (depending on dataset and GPU).
Parameters: Rank, Alpha, and Learning Rate directly affect adaptability.
Easily trained using tools like Kohya_ss or ComfyUI LoRA Trainer.
Advantages
Very lightweight and modular.
Can be stacked (e.g., face LoRA + clothing LoRA + style LoRA).
Works with existing models without permanent modification.
Faster iteration is great for creative experimentation.
Limitations
Slightly less consistent than DreamBooth for fine facial reproduction.
Requires careful prompt balance too strong weights can distort results.
Pro Tip
Blend LoRAs at different strengths (<lora:model:0.6>) to find a natural mix between styles. You can also merge multiple LoRAs into one using sd-webui merge tools for compact efficiency.
Textual Inversion: Lightweight Concept Embedding
Textual Inversion (TI) focuses on training a single token that represents a new concept. Unlike LoRA or DreamBooth, it doesn’t modify the model; it fine-tunes the text encoder, teaching a specific token to represent your subject or style.
How It Works
Input: 5–20 reference images.
Output: A single learned embedding file (.pt) containing the token data.
The token (e.g., <shivstyle>) can be used in prompts to reproduce the learned aesthetic.
Technical Highlights
File size: 4–50KB.
Training time: 15–30 minutes.
Works great for textures, patterns, art styles, lighting conditions, and simple objects.
Advantages
Extremely small and portable.
Easy to share or combine with LoRA or DreamBooth models.
Ideal for stylization or mood transfer.
Limitations
Poor at capturing detailed faces or complex structures.
Relies heavily on the base model’s knowledge.
Outputs vary depending on prompt phrasing and model version.
Pro Tip
Use concept blending to stack multiple TI tokens to combine their traits (like <painterly> <shivstyle>). It’s a great trick for stylized results.

Combining Methods for Maximum Impact
Professional creators rarely rely on a single fine-tuning technique. Instead, they combine methods for layered control:
DreamBooth + LoRA: Create a strong subject identity with DreamBooth, then use LoRA to stylize it dynamically.
LoRA + Textual Inversion: Stack small LoRAs with custom tokens for complex, style-rich outputs.
DreamBooth + Textual Inversion: Perfect for branding identity accuracy with custom tone or lighting.
Example Workflow
Train a DreamBooth model for your character.
Train LoRAs for different clothing or emotions.
Use Textual Inversion tokens for color schemes or visual filters.
Combine all three in one prompt for professional consistency.
Pro-Level Tips and Workflow Optimization
Data variety = quality output: Include 360° views and natural lighting for DreamBooth or LoRA training.
Keep prompts structured: Start minimal, then add artistic or environmental modifiers gradually.
Monitor loss curves: Stable training loss between 0.05 and 0.1 usually indicates good learning.
Use noise offset in SDXL training: Reduces grain and overfitting in LoRA fine-tunes.
Version control your models: Save checkpoints at intervals to track improvement or prevent drift.
Prompt blending: Combine learned tokens like <artiststyle> <shivface> <cyberpunk> for unique art.
Inference speed tuning: Use half-precision (FP16) for faster render times without losing quality.
DreamBooth: Deep Model-Level Fine-Tuning
Optimizer Choice Matters: Using the AdamW8bit or Lion optimizer instead of the default Adam improves convergence speed and reduces memory usage on GPUs like the RTX 3060 or 4070.
EMA (Exponential Moving Average) Checkpoints: Saving EMA checkpoints during training helps stabilize learning and produces cleaner, more consistent renders.
Gradient Checkpointing: For large models like SDXL, enabling gradient checkpointing saves up to 30–40% VRAM during training, allowing 8 GB GPUs to handle DreamBooth fine-tunes.
Precision Settings: Using mixed precision (fp16 or bf16) can speed up training by ~40% with minimal loss in visual accuracy.
Token Regularization Tuning: Adjusting the class token ratio (subject/class = 1:2) prevents model collapse, especially for human identity training.
Latent Caching: Storing latents in memory between epochs significantly reduces training time and avoids redundant VAE encoding passes.
Noise Offset & SNR Weighting: Implementing signal-to-noise ratio (SNR) balancing in loss functions improves detail retention and reduces washed-out color issues.
Prompt Conditioning: Training with multi-prompt pairs (“a photo of sks man” + “portrait of sks man in sunlight”) boosts contextual adaptability during inference.
Layer Freeze Technique: Freezing early layers (like UNet down blocks) and fine-tuning mid/high-level ones reduces overfitting and shortens training time.
Custom Scheduler Use: Using CosineWithRestartsLR instead of the default linear scheduler allows better cyclical convergence and fewer artifacts.
LoRA: Lightweight Adaptation, Modular Power
Rank (r) Control: The rank value directly defines the “resolution” of the learned features. A rank of 4–8 works for general style; 16–32 for identity-level details.
Target Module Selection: Instead of training on all UNet attention blocks, limit LoRA injection to to_q and to_v layers to preserve general model behavior.
Clip Skip Handling: For anime models (like Anything v5), using Clip Skip 2 produces better facial consistency during training and inference.
LoRA Merging Order: When stacking multiple LoRAs, the order of loading affects composition. Load the identity LoRA first, then the style LoRA for optimal results.
LoRA Scaling Behavior: A scaling value (alpha) below 1.0 tends to maintain color accuracy, while values above 1.0 enhance contrast and stylization.
Dynamic Weight Inference: Use prompt-based LoRA weighting, e.g., <lora:portrait_lora:0.8> a photo of a person in <lora:cinematic_lora:0.4> for granular control.
Quantization Support: Convert LoRAs into INT8 or FP8 quantized formats to speed up inference without visual degradation ideal for mobile or web deployment.
Autoencoder Matching: Always train LoRA with the same VAE version used in inference. Mismatched VAEs lead to color banding and texture distortion.
Noise Augmentation: Adding random Gaussian noise (0.02–0.05) to training images helps generalization and reduces overfitting.
Batch Size Tuning: For most LoRA trainings, a batch size of 2–4 with gradient accumulation performs better than higher direct batches due to adaptive learning stability.
Textual Inversion: Token-Level Learning Optimization
Embedding Vector Dimension: The Default dimension is 768 for SD 1.5 and 1024 for SDXL; higher values improve concept retention but may cause overfitting.
Learning Rate Scheduling: Use a warm-up linear scheduler (starting from 1e-6 to 5e-4) to stabilize early token learning, especially for abstract styles.
Token Multiplicity: Using multi-token embeddings (e.g., <shivstyle1> <shivstyle2>) allows learning complex subjects with separate tokens for facial and stylistic traits.
Loss Function Optimization: Replace default MSE loss with Cosine Similarity Loss for better semantic alignment between tokens and images.
Tokenizer Bias Avoidance: Avoid token names resembling common words (“art,” “photo,” “person”) as the model already associates those with generic concepts.
Embedding Merging: You can merge multiple Textual Inversion embeddings (using a simple average script) to create compound aesthetic tokens.
Prompt Dependency: TI relies heavily on prompt context and uses modifiers like lighting, mood, or medium to refine the token’s expression.
Progressive Freezing: After 70% of training, freeze token vectors to prevent overfitting and maintain generalization ability.
Seed Consistency Testing: Testing embeddings with fixed random seeds helps measure their real consistency across prompt variations.
Cross-Model Portability: Embeddings trained on SD 1.5 need rescaling to work effectively on SDXL; a scaling factor of ~1.25x improves cross-model transfer.

Hybrid Optimization & Workflow Enhancements
LoRA + TI Layered Training: Starting with a textual inversion token to establish semantic meaning, then training a LoRA over it for visual enhancement drastically reduces LoRA training time.
DreamBooth LoRA Extraction: You can convert a full DreamBooth model into a LoRA adapter using the kohya-extract-lora script, compressing a 4GB model into 150MB while preserving identity.
Dynamic Prompt Weighting: Combine different methods dynamically, e.g., (shivman:1.2) wearing <lora:fashionlora:0.8> to balance subject precision with style control.
Memory-Efficient Fine-Tuning: Use xformers or bitsandbytes libraries during training to halve VRAM usage on consumer GPUs.
Multi-Concept Fusion: Fine-tune different concepts separately (e.g., hairstyle, clothing, lighting), then use prompt-based mixing for complete character creation.
FP8 Acceleration: On RTX 40-series GPUs, enabling FP8 precision in LoRA training improves throughput by up to 70% without noticeable quality loss.
Automatic Captioning Integration: Tools like BLIP or DeepBooru can auto-generate captions for datasets, ensuring better alignment between image and text during training.
Model Compatibility:
DreamBooth: Works best with base checkpoints.
LoRA: Flexible across derived checkpoints.
Textual Inversion: Sensitivity to tokenizer variations must match the model version exactly.
Embedding Visualization: Using PCA projection (Principal Component Analysis) to visualize how your LoRA or TI embeddings evolve over epochs helps detect mode collapse early.
Post-Training Validation Pipeline:
Always test on:
Neutral prompts (no modifiers)
Extreme prompts (unusual settings)
Style variation prompts
This ensures your trained concept generalizes well instead of memorizing training data.
Deployment & Model Management
Checkpoint Segmentation: Split large fine-tuned DreamBooth checkpoints into modular .safetensors segments for version control and easier merging.
LoRA AutoLoader Scripts: Use automatic LoRA injectors that load LoRAs dynamically based on keywords in prompts, ideal for automated AI workflows or web apps.
Textual Inversion Libraries: Store multiple embeddings as a JSON mapping for rapid integration into production environments without manual loading.
Cross-Platform Conversion: Convert LoRAs to ONNX format for use in mobile or real-time inference engines (like TensorRT).
Batch Prompt Inference: For large-scale generation, use the Diffusers Pipeline API with batched LoRA+TI calls to generate multiple stylized images simultaneously.
Future of Fine-Tuning
The next generation of diffusion systems like Stable Diffusion 3 and FLUX will likely merge these approaches. Expect LoRA-like adapters baked into UI tools, token-based training without coding, and multi-subject learning that merges faces, products, and scenes seamlessly.
In short, fine-tuning is moving from a technical niche to a creative essential, just like color grading or 3D modeling once did.
DreamBooth, LoRA, and Textual Inversion represent the three pillars of AI personalization: depth, flexibility, and efficiency.
DreamBooth gives you unmatched accuracy.
LoRA provides speed, modularity, and creativity.
Textual Inversion adds light, portable customization.
Mastering these methods means you’re not just generating AI art; you’re crafting a personal visual language.

FAQ's
Q: What is the main difference between DreamBooth, LoRA, and Textual Inversion?
DreamBooth modifies the entire AI model to learn a specific subject or person in detail, LoRA adds lightweight trainable layers for efficient style or identity adaptation, and Textual Inversion teaches a token (word) to represent a concept without altering the model. In short:
DreamBooth = Full model fine-tune (heavy but detailed)
LoRA = Lightweight add-on (efficient and modular)
Textual Inversion = Token-based tweak (simple and portable)
Q: Which method gives the most realistic and accurate results?
DreamBooth produces the most photorealistic and accurate results, especially for human faces, products, or branded visuals. It captures intricate features like lighting, skin tone, and expressions better than the other two methods.
Q: Can I combine DreamBooth, LoRA, and Textual Inversion together?
Yes. In fact, combining them is common practice among professionals. You can train a DreamBooth model for accuracy, apply LoRA layers for style variation, and use Textual Inversion tokens for specific aesthetic or lighting effects. This multi-layer approach maximizes both creativity and precision.
Q: Is LoRA training faster than DreamBooth?
Absolutely. LoRA training usually takes 20–60 minutes, compared to 2–6 hours for DreamBooth. It also requires less GPU memory (as low as 8GB). This makes LoRA ideal for quick iterations or style-focused projects.
Q: Can I train these models on a regular consumer GPU or laptop?
Yes, but with limits.
DreamBooth: Needs at least 12GB VRAM (e.g., RTX 3060 or higher).
LoRA: Works well on 6–8GB GPUs.
Textual Inversion: Can run comfortably on 4–6GB GPUs.
For low-end systems, cloud-based solutions like Google Colab, RunPod, or Paperspace are great alternatives.
Q: Do LoRA and Textual Inversion affect the original Stable Diffusion model?
No. Both methods are non-destructive. They don’t alter the original model’s weights; they simply “plug in” during inference. You can add or remove them anytime without modifying the base checkpoint.
Q: How many images do I need to train effectively?
DreamBooth: 4–10 high-quality, varied photos.
LoRA: 10–30 well-captioned images for complex subjects.
Textual Inversion: 5–20 images depending on the complexity of the concept.
More images are not always better; variety matters more than quantity.
Q: What’s the best file format and resolution for training images?
Use PNG or high-quality JPG files with resolutions between 512x512 and 768x768 pixels. Consistent framing, clean lighting, and minimal compression improve training quality significantly.
Q: How do I know if my model is overfitting?
Overfitting happens when the model memorizes your training images instead of generalizing the concept. Signs include:
Nearly identical reproductions of training photos
Blurry or inconsistent results in new prompts
Poor adaptability in different environments
To fix this, lower learning rates, add regularization images, or increase dataset variety.
Q: Can I sell or share my trained models publicly?
Yes, but with caution.
Make sure your training data doesn’t contain copyrighted or private material.
Credit the base model developers (e.g., Stable Diffusion, RunwayML).
Use open licenses like CreativeML Open RAIL if you plan to distribute models commercially.
Q: Which method is best for stylized or anime artwork?
LoRA is the preferred choice for stylized or anime-based training because of its lightweight architecture and flexibility. It allows for fine style blending, character consistency, and dynamic expression without retraining the full model.
Q: Is there a risk of data leakage or privacy issues with DreamBooth?
Yes, if trained on private or copyrighted faces. Since DreamBooth fine-tunes the base model itself, it can unintentionally store detailed likeness data. Always use consensual or public-domain content for ethical and legal compliance.
Q: Can Textual Inversion learn both style and object appearance?
Yes, but with limitations. Textual Inversion works best for textures, patterns, and stylistic cues (like “neon lighting” or “oil painting”). It can represent simple objects, but it struggles with faces or detailed 3D forms.
Q: What tools or UIs can I use for training these methods?
Popular tools include:
AUTOMATIC1111 WebUI (for LoRA & Textual Inversion)
Kohya_ss GUI (for LoRA & DreamBooth with SDXL support)
ComfyUI (modular node-based workflows)
Hugging Face Diffusers Library (for Python-based fine-tuning)
Q: How do I balance multiple LoRAs or tokens in a single prompt?
Use weighting syntax like:
<lora:portraitLora:0.7> <lora:lightingLora:0.5> a photo of <shivstyle> person in a garden
The numbers (0.1–1.0) control each LoRA’s intensity. Finding the right balance takes experimentation; it’s part of the creative process.
Q: Can I transfer a LoRA or Textual Inversion trained on SD 1.5 to SDXL?
Yes, but not directly. You’ll need to retrain or adjust scaling factors, as SDXL uses different tokenization and attention structures. A 1.25x learning rate or re-embedding often helps bridge models effectively.
Q: How can I keep colors accurate during training?
Use a consistent VAE (Variational Autoencoder) during both training and inference. Mismatched VAEs often cause color shifting or banding issues in DreamBooth and LoRA results.
Q: Which method is future-proof for next-gen AI models?
LoRA is currently the most adaptable for evolving architectures like SDXL, Flux, and Stable Diffusion 3. It integrates easily, consumes less storage, and can be updated or merged without retraining from scratch.
Subscribe To Our Newsletter
All © Copyright reserved by Accessible-Learning Hub
| Terms & Conditions
Knowledge is power. Learn with Us. 📚

