
ALIGN vs. MetaCLIP: Architecture, Features, and Key Differences Explained
Explore an in-depth comparison of ALIGN vs. MetaCLIP, two powerful vision-language models developed by Google and Meta. Discover their architectures, training methodologies, technical differences, and real-world applications in AI-driven image and text understanding.
AI ASSISTANTAI/FUTURECOMPANY/INDUSTRYEDITOR/TOOLS
Sachin K Chaurasiya
3/15/20254 min read


In the fast-evolving domain of AI-driven vision-language models, ALIGN (A Large-scale ImaGe and Noisy-text embedding) and MetaCLIP stand out as powerful frameworks. These models play a crucial role in bridging the gap between visual understanding and textual descriptions, powering applications like image search, content moderation, and automated captioning. But how do they compare? This article delves into ALIGN vs. MetaCLIP, exploring their architectures, capabilities, training methodologies, technical details, and use cases.
What is ALIGN?
ALIGN, developed by Google Research, is a vision-language model designed to map images and text into a shared embedded space. Unlike conventional approaches, ALIGN leverages massive-scale noisy web data without requiring manual annotations.
Technical Details of ALIGN
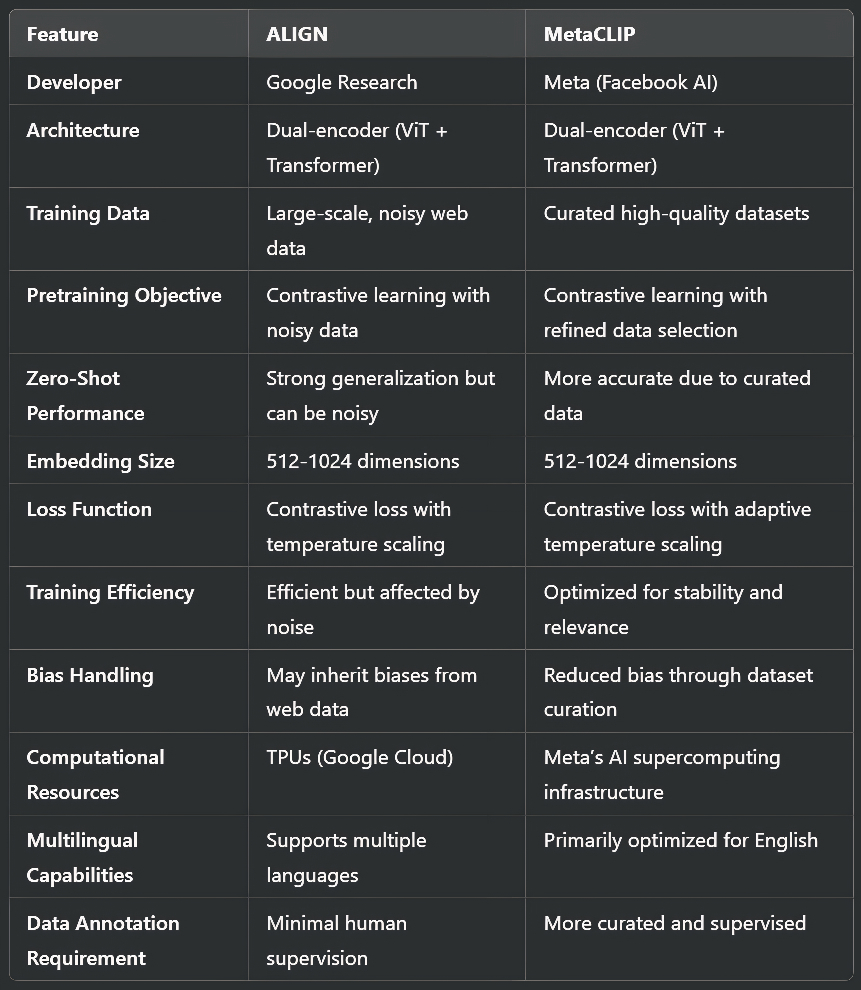
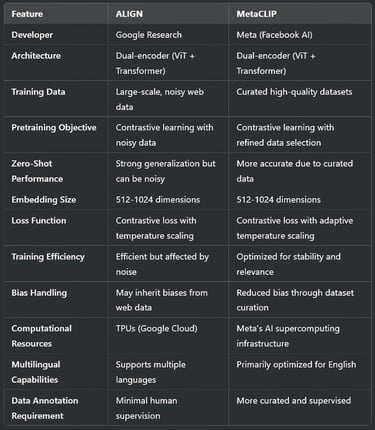
Model Architecture: ALIGN employs a dual-encoder architecture with a vision transformer (ViT) and a text transformer (BERT-like model). Both encoders map image and text into a common latent space.
Pretraining Objective: ALIGN uses contrastive learning to align image and text representations, maximizing similarity for matched pairs and minimizing it for mismatched pairs.
Dataset Size: Trained on billions of noisy image-text pairs sourced from the internet, without human supervision.
Embedding Dimension: Typically in the range of 512 to 1024 dimensions for efficient similarity computations.
Loss Function: Contrastive loss with a temperature parameter to adjust the sharpness of similarity distributions.
Computational Resources: Trained on TPUs (Tensor Processing Units) with thousands of GPU-equivalent compute power.
Training Time: Several weeks of training on massive parallel hardware to optimize generalization.
Multilingual Support: Uses a multilingual text encoder, allowing cross-lingual retrieval and captioning.
Use Cases
Image Search & Retrieval: Enhances search engines by understanding image context through text queries.
Content Moderation: Detects inappropriate images and text combinations.
Zero-Shot Classification: Recognizes unseen categories by generalizing learned embeddings.
Automated Visual Tagging: Can assign relevant tags to images without predefined labels.
Multimodal AI Assistants: Powers AI chatbots and digital assistants with vision-language capabilities.


What is MetaCLIP?
MetaCLIP, developed by Meta (formerly Facebook), is an advanced iteration inspired by OpenAI’s CLIP (Contrastive Language-Image Pretraining). It refines contrastive learning approaches by improving data quality, training stability, and model efficiency.
Technical Details
Model Architecture: Like ALIGN, MetaCLIP uses a dual-encoder setup with a vision transformer (ViT) for images and a transformer-based text encoder.
Training Data: Uses curated datasets with high-quality image-text pairs, reducing noise compared to ALIGN.
Pretraining Objective: Employs contrastive learning with improved data selection to enhance text-image alignment.
Embedding Size: Typically in the range of 512 to 1024 dimensions, optimized for retrieval efficiency.
Training Loss: Utilizes contrastive loss with adaptive temperature scaling for stable convergence.
Bias Reduction: Incorporates fairness adjustments by filtering and balancing training data distributions.
Compute Optimization: MetaCLIP is optimized for large-scale distributed training on Meta’s AI supercomputing infrastructure.
Performance Metrics: Outperforms traditional CLIP on zero-shot classification tasks, showing higher accuracy and robustness.
Use Cases
Visual Question Answering (VQA): Helps AI systems understand images in response to textual queries.
Automated Captioning: Generates highly accurate descriptions of images with contextual awareness.
AI-Assisted Content Creation: Powers applications like AI-generated art and text-based video generation.
Personalized Recommendations: Enhances product recommendations by analyzing image and text data together.
Medical Image Analysis: Assists in understanding and labeling medical scans through text descriptions.
Which Model is Better?
The choice between ALIGN and MetaCLIP depends on specific use cases:
If you need a model that can handle large-scale, diverse, and noisy web-based data, ALIGN is a solid choice due to its massive training corpus.
If your focus is on high accuracy, reduced bias, and refined embeddings, MetaCLIP is more reliable due to its better dataset curation and training efficiency.
For tasks requiring zero-shot learning with high interpretability, MetaCLIP edges ahead with better generalization capabilities.
For applications where scale and breadth of data are crucial, ALIGN’s web-scale approach proves advantageous.
If multilingual support is important, ALIGN has an edge over MetaCLIP, which is primarily optimized for English.
For medical or highly specialized AI applications, MetaCLIP’s fine-grained understanding makes it a better choice.
FAQs
What is the main difference between ALIGN and MetaCLIP?
ALIGN, developed by Google, is trained on large-scale noisy web data, making it highly scalable but prone to some inaccuracies. MetaCLIP, by Meta, focuses on curated datasets, resulting in better accuracy and lower bias.
Which model performs better for zero-shot learning?
MetaCLIP generally outperforms ALIGN in zero-shot classification due to its refined training data, but ALIGN’s massive dataset allows broader generalization.
How do ALIGN and MetaCLIP handle multilingual support?
ALIGN is designed with multilingual capabilities, while MetaCLIP primarily focuses on English but can be fine-tuned for other languages.
Which model is more efficient in terms of computational resources?
MetaCLIP is optimized for efficiency with curated training data and stability improvements. ALIGN, while powerful, requires extensive TPU resources due to its vast dataset.
Can these models be fine-tuned for specific industries like healthcare or finance?
Yes, both ALIGN and MetaCLIP can be fine-tuned for domain-specific applications, such as medical imaging, financial document analysis, and AI-powered content creation.
Which model is better for image search and retrieval?
ALIGN is often preferred for large-scale image search due to its vast dataset, while MetaCLIP excels in delivering more accurate and refined search results.
Future of Vision-Language Models
Both ALIGN and MetaCLIP represent the forefront of AI research in vision-language models. However, as AI advances, several trends will shape the next generation of such models:
Hybrid Training Approaches: Combining self-supervised learning with human-annotated data to improve accuracy while maintaining scalability.
Bias Reduction Strategies: Ensuring fairness and reducing the impact of biased datasets on AI decision-making.
Better Cross-Language Capabilities: Expanding support for non-English languages to make AI more inclusive.
Domain-Specific Fine-Tuning: Training models for medical, legal, and specialized fields to enhance their usability.
Multimodal AI Evolution: Integrating video, audio, and text for a more holistic understanding of content.
Both ALIGN and MetaCLIP represent cutting-edge advancements in vision-language models, each excelling in different aspects. ALIGN’s strength lies in its scalability and ability to learn from vast, uncurated datasets, while MetaCLIP focuses on precision, robustness, and efficiency.
As AI-driven applications continue to grow, these models will play an essential role in shaping the future of multimodal learning and AI-powered content understanding.
Subscribe To Our Newsletter
All © Copyright reserved by Accessible-Learning Hub
| Terms & Conditions
Knowledge is power. Learn with Us. 📚

